In my previous post on CMIS, I introduced the Content Management Interoperability Services (CMIS) specification and the Apache Chemistry project. You learned that CMIS gives you a language-neutral, vendor-independent way to perform CRUD functions against any CMIS-compliant server using a standard API. I showed a simple CMIS query being executed from a Groovy script running in the OpenCMIS Workbench.
Now I’d like to get a little more detailed and show a simple use case: I’ll use the OpenCMIS client library for Java to upload some files from my local machine to a CMIS repository. In my case, that repository is Alfresco 4.2.c Community Edition running locally, but this code should work with any CMIS-compliant server from vendors like IBM, EMC, Microsoft, Nuxeo, and so on. I’ll include the relevant snippets, but if you want to follow along, the full source code for this example lives here. I use that example to show the same code working against Alfresco in the cloud and Alfresco on-premise. If you are running against on-premise only or some other CMIS server, it has a few dependencies that won’t be relevant to you.
LoadFiles.java is a runnable Java class. The main method simply calls doExample(). That method grabs a session, gets a handle to the destination folder for the files on the local machine, and then, for each file in the local machine’s directory, it creates a hashmap of metadata values, then uploads each file and its associated metadata to the repository. Let’s look at each of these pieces in turn.
Get a Session
The first thing you need is a session. I have a getCmisSession() method that knows how to get one, and it looks like this:
SessionFactory factory = SessionFactoryImpl.newInstance();
Map parameter = new HashMap();
// connection settings
parameter.put(SessionParameter.ATOMPUB_URL, ATOMPUB_URL);
parameter.put(SessionParameter.BINDING_TYPE, BindingType.ATOMPUB.value());
parameter.put(SessionParameter.AUTH_HTTP_BASIC, "true");
parameter.put(SessionParameter.USER, USER_NAME);
parameter.put(SessionParameter.PASSWORD, PASSWORD);
List repositories = factory.getRepositories(parameter);
return repositories.get(0).createSession();
As you can see, establishing a session is as simple as providing the username, password, binding, and service URL. The binding is the protocol we’re going to use to talk to the server. In CMIS 1.0, usually the best choice is the Atom Pub binding because it is faster than the Web Services binding, the only other alternative. CMIS 1.1 adds a browser binding that is based on HTML forms and JSON but I won’t cover that here.
The other parameter that gets set is the service URL. This is server-specific. For Alfresco 4.x or higher, the CMIS 1.0 Atom Pub URL is http://localhost:8080/alfresco/cmisatom.
The last thing the method does is return a session for a specific repository. CMIS servers can serve more than one repository. In Alfresco’s case, there is only ever one, so it is safe to return the first one in the list.
Get the Target Folder
Okay, we’ve got a session with the CMIS server’s repository. The repository is a hierarchical tree of objects (folders and documents) similar to a local file system. The class is configured with a parent folder path and the name of a new folder that should be created in that parent folder. So the first thing we need to do is get a reference to the parent folder. My example getParentFolder() method just grabs the folder by path, like this:
Folder folder = (Folder) cmisSession.getObjectByPath(FOLDER_PATH);
return folder;
Now, given the parent folder and the name of a new folder, the createFolder() method attempts to create the new folder to hold our files:
Folder subFolder = null;
try {
subFolder = (Folder) cmisSession.getObjectByPath(parentFolder.getPath() + "/" + folderName);
System.out.println("Folder already existed!");
} catch (CmisObjectNotFoundException onfe) {
Map props = new HashMap();
props.put("cmis:objectTypeId", "cmis:folder");
props.put("cmis:name", folderName);
subFolder = parentFolder.createFolder(props);
String subFolderId = subFolder.getId();
System.out.println("Created new folder: " + subFolderId);
}
return subFolder;
The folder is either going to already exist, in which case we’ll just grab it and return it, or it will need to be created. We can test the existence of the folder by trying to fetch it by path, and if it throws a CmisObjectNotFoundException, we’ll create it.
Look at the Map that is getting set up to hold the properties of the folder. The minimum required properties that need to be passed in are the type of folder to be created (“cmis:folder”) and the name of the folder to create. You might choose to extend your server’s content model with your own folder types. In this example, the out-of-the-box “cmis:folder” type is fine.
Set Up the Properties For Each New Document
Just like when the folder was created, every file we upload to the repository will have its own set of metadata. To make it interesting, though, we’ll provide more than just the type of document we want to create and the name of the document. In my example, I’m using a content model we created for the CMIS & Apache Chemistry in Action book. It contains several types. One of which is called “cmisbook:image”. The image type has attributes you’d expect that would be part of an image, like height, width, focal length, camera make, ISO speed, etc. In fact, if you use the OpenCMIS Workbench, you can inspect the type definition for cmisbook:image. Here’s a screenshot (click to enlarge):
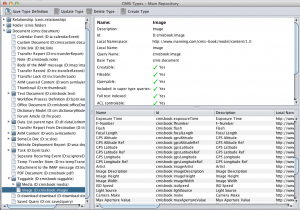
Two of the properties I’m going to work with in this example are the latitude and longitude. Alfresco will automatically extract metadata like this when you add files to the repository. In fact, Alfresco already has a “geographic aspect” out-of-the-box that can be used to extract and store lat and long. But we wanted this content model to work with any CMIS repository and not all repositories support aspects (CMIS 1.1 call these “secondary types”) so the content model used in the book defines lat and long on the cmisbook:image type.
Because not all repositories know how to extract metadata, we’re going to use Apache Tika to do it in our client app.
The getProperties() method does this work. It returns a Map of properties that consists of the type of the object we want to create (“cmisbook:image”), the name of the object (the file name being uploaded), and the latitude and longitude. Here’s what that code looks like:
Map props = new HashMap();
String fileName = file.getName();
System.out.println("File: " + fileName);
InputStream stream = new FileInputStream(file);
try {
Metadata metadata = new Metadata();
ContentHandler handler = new DefaultHandler();
Parser parser = new JpegParser();
ParseContext context = new ParseContext();
metadata.set(Metadata.CONTENT_TYPE, FILE_TYPE);
parser.parse(stream, handler, metadata, context);
String lat = metadata.get("geo:lat");
String lon = metadata.get("geo:long");
stream.close();
// create a map of properties
props.put("cmis:objectTypeId", objectTypeId);
props.put("cmis:name", fileName);
if (lat != null && lon != null) {
System.out.println("LAT:" + lat);
System.out.println("LON:" + lon);
props.put("cmisbook:gpsLatitude", BigDecimal.valueOf(Float.parseFloat(lat)));
props.put("cmisbook:gpsLongitude", BigDecimal.valueOf(Float.parseFloat(lon)));
}
} catch (TikaException te) {
System.out.println("Caught tika exception, skipping");
} catch (SAXException se) {
System.out.println("Caught SAXException, skipping");
} finally {
if (stream != null) {
stream.close();
}
}
return props;
Now we have everything we need to upload the file to the repository: a session, the target folder, and a map of properties for each object being uploaded. All that’s left to do is upload the file.
Upload the File
The first thing the createDocument() method does is to make sure that we have a Map with the minimal set of metadata, which is the object type and the name. It’s conceivable that things didn’t go well in the getProperties() method, and if that is the case, this bit of code makes sure everything is in place:
String fileName = file.getName();
// create a map of properties if one wasn't passed in
if (props == null) {
props = new HashMap<String, Object>();
}
// Add the object type ID if it wasn't already
if (props.get("cmis:objectTypeId") == null) {
props.put("cmis:objectTypeId", "cmis:document");
}
// Add the name if it wasn't already
if (props.get("cmis:name") == null) {
props.put("cmis:name", fileName);
}
Next we use the file and the object factory on the CMIS session to set up a ContentStream object:
ContentStream contentStream = cmisSession.getObjectFactory().
createContentStream(
fileName,
file.length(),
fileType,
new FileInputStream(file)
);
And finally, the file can be uploaded.
Document document = null;
try {
document = parentFolder.createDocument(props, contentStream, null);
System.out.println("Created new document: " + document.getId());
} catch (CmisContentAlreadyExistsException ccaee) {
document = (Document) cmisSession.getObjectByPath(parentFolder.getPath() + "/" + fileName);
System.out.println("Document already exists: " + fileName);
}
return document;
Similar to the folder creating logic earlier, it could be that the document already exists, so we use the same find-or-create pattern here.
When I run this locally using a folder that contains five pics I snapped in Berlin, the output looks like this:
Created new folder: workspace://SpacesStore/2f576635-5058-4053-9a61-dad68939fdd2
File: augustiner.jpg
LAT:52.51387
LON:13.39111
Created new document: workspace://SpacesStore/b19755e1-74a2-4c1e-9eb5-a5bfd2c0ebd7;1.0
File: berlin_cathedral.jpg
LAT:52.51897
LON:13.39936
Created new document: workspace://SpacesStore/34aa7b80-9f09-4c07-a040-9aee94debf80;1.0
File: brandenburg.jpg
LAT:52.51622
LON:13.37783
Created new document: workspace://SpacesStore/6c02f8f6-accc-4997-be5c-601bc7131247;1.0
File: gendarmenmarkt.jpg
LAT:52.51361
LON:13.39278
Created new document: workspace://SpacesStore/44ff28e7-782a-46c3-b388-453fd8495472;1.0
File: old_museum.jpg
LAT:52.52039
LON:13.39926
Created new document: workspace://SpacesStore/03a85605-4a66-4f94-b423-82502efbca4a;1.0
Now Run Against Another Vendor’s Repo
What’s kind of cool, and what I think really demonstrates the great thing about CMIS, is that you can run this class against any CMIS repository, virtually unchanged. To demonstrate this, I’ll fire up the Apache Chemistry InMemory Repository we ship with the source code that accompanies the book because it is already configured with a custom content model that includes “cmisbook:image”. As the name suggests, this repository is a reference CMIS server available from Apache Chemistry that runs entirely in-memory.
To run the class against the Apache Chemistry InMemory Repository, we have to change the service URL and the content type ID, like this:
//public static final String CONTENT_TYPE = "D:cmisbook:image";
public static final String CONTENT_TYPE = "cmisbook:image";
//public static final String ATOMPUB_URL = ALFRESCO_API_URL + "alfresco/cmisatom";
public static final String ATOMPUB_URL = ALFRESCO_API_URL + "inmemory/atom";
And when I run the class, my photos get uploaded to a completely different repository implementation.
That’s It!
That’s a simple example, I know, but it illustrates fetching objects, creating new objects, including those of custom types, setting metadata, and handling exceptions all through an industry-standard API. There is a lot more to CMIS and OpenCMIS, in particular. I invite you to learn more by diving in to CMIS & Apache Chemistry in Action!

 Hopefully, you find the Alfresco community team and our company in general extremely approachable. My perception is that people aren’t afraid to reach out and give us feedback directly, which is exactly how we like it. But I think it is important for us to stop and ask for specific feedback on areas we are tracking on a regular basis. That’s why we do a survey of the Alfresco community every year.
Hopefully, you find the Alfresco community team and our company in general extremely approachable. My perception is that people aren’t afraid to reach out and give us feedback directly, which is exactly how we like it. But I think it is important for us to stop and ask for specific feedback on areas we are tracking on a regular basis. That’s why we do a survey of the Alfresco community every year.
 The months leading up to
The months leading up to 


