
![]() Nextcloud Files is an open source solution for file sync and share. Think Dropbox, but distributed under an open source license (GNU AGPLv3) and installed your own servers. Today I decided to see what their latest release, version 13, has to offer.
Nextcloud Files is an open source solution for file sync and share. Think Dropbox, but distributed under an open source license (GNU AGPLv3) and installed your own servers. Today I decided to see what their latest release, version 13, has to offer.
Much like any web-based file sharing app you’ve seen, upon logging in to Nextcloud a user is presented with a list of their folders and files. Unlike more general Document Management or ECM repositories where the default mode of operation is typically that there is this giant repository of everything that a user may or may not be able to see, Nextcloud, by default, is user-centric–users see their own folders and files and chooses to share those with one or more team members.
With that said, there is a “group folders” feature that allows administrators to define folders shared by groups of users. That feature is not enabled by default, but it can be turned on in a couple of clicks.
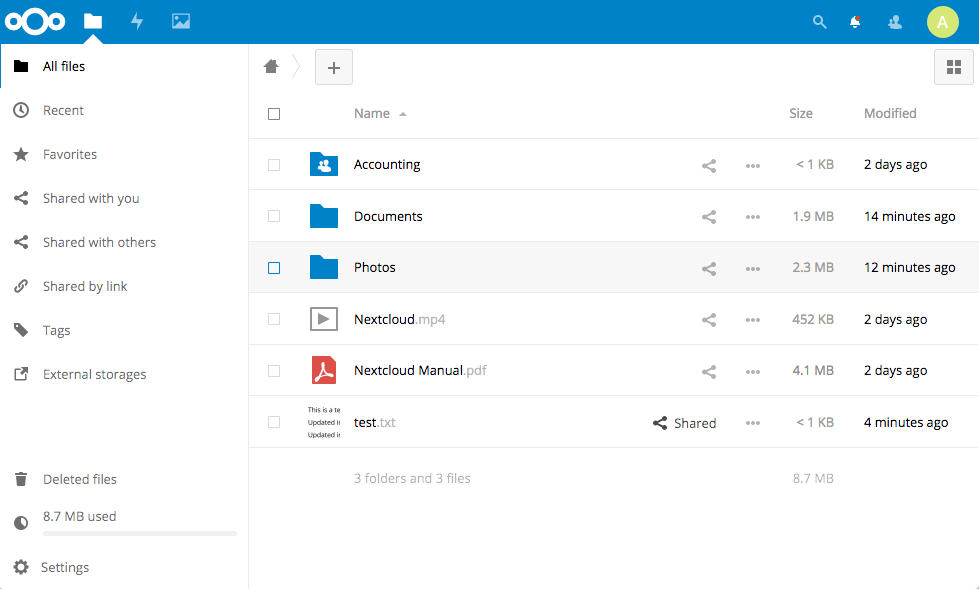 The functionality is what you’d expect from basic file sync and share. You can:
The functionality is what you’d expect from basic file sync and share. You can:
- Drag-and-drop one or more files into a folder to upload
- Move, copy, and rename files and folders
- Preview PDFs, images, and other file types
- Share folders and files with users and groups, including setting an expiration date after which the item is no longer shared
- Tag folders and files
- Favorite folders and files
- See a filterable activity stream of recent activity
- Recover deleted documents from the trashcan
In addition to the browser-based user interface, iOS and Android users can download the Nextcloud mobile apps. Windows, macOS, and Linux users can download a desktop app. Regardless of your platform, these apps sync content between your devices and the Nextcloud server. Nextcloud also supports WebDAV, so if you already have a WebDAV client you like, you can use it to manage your files in Nextcloud.
There are a number of useful administrative features in Nextcloud, including:
- Configuring authentication to leverage LDAP/AD
- Server-side encryption of data at-rest (although the docs say this is not supported for group folders)
- Linking to external storage using providers such as Amazon S3, FTP, OpenStack Object Storage, SMB, and WebDAV
- The ability to federate your Nextcloud server with other Nextcloud or Pydio servers
- Outlook and Thunderbird integration
If there are features you’d like to see that are not installed by default, they might be available in a community-developed app. Administrators can browse the currently installed applications as well as search for new applications to install without leaving the Nextcloud application. Noteworthy applications include integrations with Collabora Online and ONLYOFFICE, which are two online office suites similar to Google Docs, Metadata, which is an app for showing metadata extracted from files such as images, and Deck, which is a Trello-like kanban board for project management.
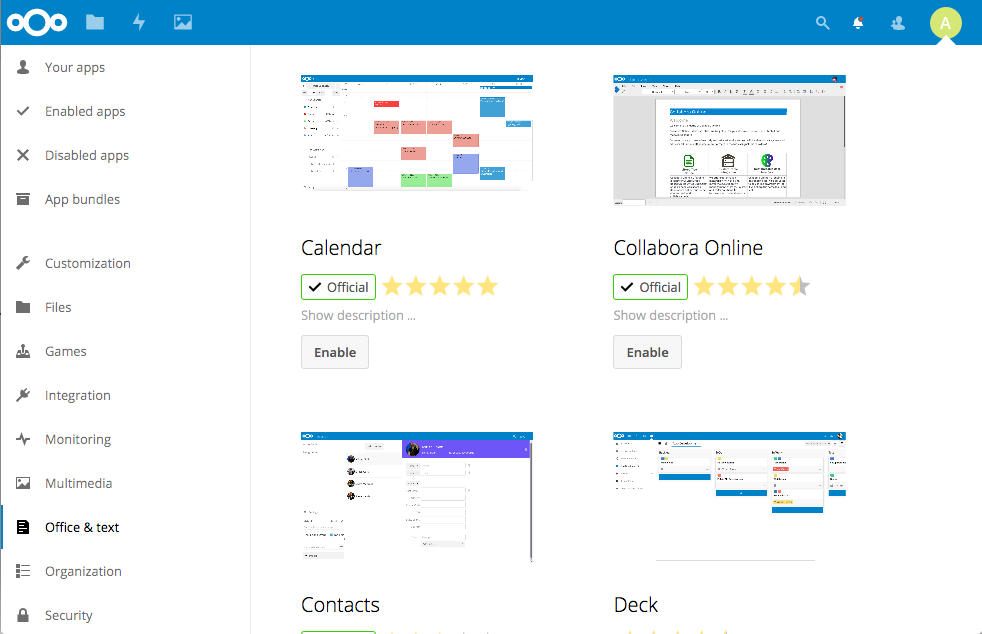 If there is nothing in the Nextcloud app store that meets your needs you can always develop your own. The Developer Documentation includes a small tutorial and API documentation.
If there is nothing in the Nextcloud app store that meets your needs you can always develop your own. The Developer Documentation includes a small tutorial and API documentation.
Installing Nextcloud is quite easy. All you need is a web server, PHP, and a database such as MariaDB or PostgreSQL. The Administration Manual includes installation details. Leveraging that, I had everything up-and-running on an Ubuntu server in about ten minutes.
For the tinkerers in the crowd, you might be interested in Nextcloud Box. It is essentially a case, a hard drive, and a place to put your own Raspberry Pi (model 2 or 3) running the Nextcloud-provided microSD card. Once assembled you’ve got yourself an open source file sync and share server that looks great, is energy efficient, and removes the middleman from your file sharing needs. I’ve got a Synology Diskstation that I really like, but I love the open source DIY aspect of the Nextcloud Box.
Will it work for an “enterprise”?
To be sure, Nextcloud is not a full-scale, Enterprise Content Management repository. But not everyone needs one of those. What is it missing? A traditional ECM repository typically includes features like:
- Custom metadata models
- Fine-grained access control
- Workflow/business process management
- Standards-based, RESTful API (beyond WebDAV)
- More complex transformation and rendering options
- Full-text search out-of-the-box
- Rules, events, or other “hooks” where custom logic can be added
- Records Management functionality
Maybe you need those features and maybe you don’t. I often see people install and maintain a traditional open source ECM repository only to use its very basic file-sharing features, never progressing beyond that. If a company is early in its “ECM maturity” and plans to eventually take advantage of the more powerful features, then it’s acceptable to under-utilize your ECM platform for a time. But if the organization just needs a glorified file share that has good sync and sharing functionality with a nice user interface and the ability to manage files via WebDAV, Nextcloud might be the perfect fit.
I should also add that if you don’t want to support Nextcloud yourself, the commercial company behind the project has various pricing plans available based on the number of users and the SLA required.





 This little beauty is an
This little beauty is an {kind=link}