There is a new version of Alfresco Rule Management available. The core purpose of the add-on is to make it easier to work with rules programmatically. For example, using the add-on you can easily convert existing standalone rules to shared rules or move rules from one folder to another.
The new release, 1.1.0, includes a small but handy feature: It adds an API for retrieving a JSON representation of all the rules set on a specified folder. The response includes everything you could ever want to know about the rules, including the conditions, actions, and parameters.
There are a variety of use cases for this. One recent client uses it to index all of their rules into a search engine so they can see how rules are being used across their repository.
As always, if you find an improvement you’d like to see in this add-on, pull requests are welcome.
Nextcloud Files is an open source solution for file sync and share. Think Dropbox, but distributed under an open source license (GNU AGPLv3) and installed your own servers. Today I decided to see what their latest release, version 13, has to offer.
Much like any web-based file sharing app you’ve seen, upon logging in to Nextcloud a user is presented with a list of their folders and files. Unlike more general Document Management or ECM repositories where the default mode of operation is typically that there is this giant repository of everything that a user may or may not be able to see, Nextcloud, by default, is user-centric–users see their own folders and files and chooses to share those with one or more team members.
With that said, there is a “group folders” feature that allows administrators to define folders shared by groups of users. That feature is not enabled by default, but it can be turned on in a couple of clicks.
The functionality is what you’d expect from basic file sync and share. You can:
Drag-and-drop one or more files into a folder to upload
Move, copy, and rename files and folders
Preview PDFs, images, and other file types
Share folders and files with users and groups, including setting an expiration date after which the item is no longer shared
Tag folders and files
Favorite folders and files
See a filterable activity stream of recent activity
Recover deleted documents from the trashcan
In addition to the browser-based user interface, iOS and Android users can download the Nextcloud mobile apps. Windows, macOS, and Linux users can download a desktop app. Regardless of your platform, these apps sync content between your devices and the Nextcloud server. Nextcloud also supports WebDAV, so if you already have a WebDAV client you like, you can use it to manage your files in Nextcloud.
There are a number of useful administrative features in Nextcloud, including:
Configuring authentication to leverage LDAP/AD
Server-side encryption of data at-rest (although the docs say this is not supported for group folders)
Linking to external storage using providers such as Amazon S3, FTP, OpenStack Object Storage, SMB, and WebDAV
The ability to federate your Nextcloud server with other Nextcloud or Pydio servers
Outlook and Thunderbird integration
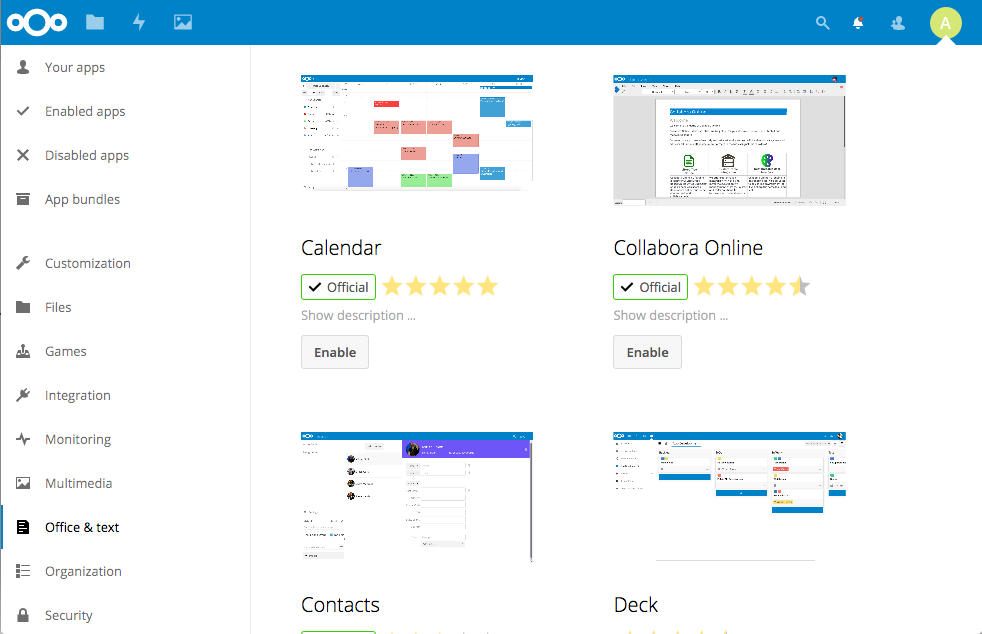
If there are features you’d like to see that are not installed by default, they might be available in a community-developed app. Administrators can browse the currently installed applications as well as search for new applications to install without leaving the Nextcloud application. Noteworthy applications include integrations with Collabora Online and ONLYOFFICE, which are two online office suites similar to Google Docs, Metadata, which is an app for showing metadata extracted from files such as images, and Deck, which is a Trello-like kanban board for project management.
If there is nothing in the Nextcloud app store that meets your needs you can always develop your own. The Developer Documentation includes a small tutorial and API documentation.
Installing Nextcloud is quite easy. All you need is a web server, PHP, and a database such as MariaDB or PostgreSQL. The Administration Manual includes installation details. Leveraging that, I had everything up-and-running on an Ubuntu server in about ten minutes.
For the tinkerers in the crowd, you might be interested in Nextcloud Box. It is essentially a case, a hard drive, and a place to put your own Raspberry Pi (model 2 or 3) running the Nextcloud-provided microSD card. Once assembled you’ve got yourself an open source file sync and share server that looks great, is energy efficient, and removes the middleman from your file sharing needs. I’ve got a Synology Diskstation that I really like, but I love the open source DIY aspect of the Nextcloud Box.
Will it work for an “enterprise”?
To be sure, Nextcloud is not a full-scale, Enterprise Content Management repository. But not everyone needs one of those. What is it missing? A traditional ECM repository typically includes features like:
Custom metadata models
Fine-grained access control
Workflow/business process management
Standards-based, RESTful API (beyond WebDAV)
More complex transformation and rendering options
Full-text search out-of-the-box
Rules, events, or other “hooks” where custom logic can be added
Records Management functionality
Maybe you need those features and maybe you don’t. I often see people install and maintain a traditional open source ECM repository only to use its very basic file-sharing features, never progressing beyond that. If a company is early in its “ECM maturity” and plans to eventually take advantage of the more powerful features, then it’s acceptable to under-utilize your ECM platform for a time. But if the organization just needs a glorified file share that has good sync and sharing functionality with a nice user interface and the ability to manage files via WebDAV, Nextcloud might be the perfect fit.
I should also add that if you don’t want to support Nextcloud yourself, the commercial company behind the project has various pricing plans available based on the number of users and the SLA required.
I love virtual machines and containers because they make it easy to isolate the applications and dependencies I’m using for a particular project. Tools like Docker, Virtualbox, and vagrant are indispensable for most of my projects and I’m still using those, but in this post I’ll describe a product called Antsle which has given me additional flexibility and has freed up some local resources.
My daily developer workstation is a MacBook Pro with 16 GB of RAM and a 500 GB SSD. From a memory and CPU perspective, it can handle running a handful of virtual machines simultaneously without a problem. But disk space is starting to be an issue.
I use vagrant and Ansible to make virtual machine provisioning repeatable–I can delete any VM at any time without remorse because I can always recreate it easily. But I get tired of continually cleaning up machines and pruning back base boxes just to reclaim space.
I decided to do something about it. My options were:
When Apple releases a MacBook Pro that can take 32 GB of RAM, buy that with at least 1 TB SSD, then continue with my current toolset.
Buy a Mac Pro or some other desktop to use exclusively for virtual machines.
Buy or build an actual server and set it up with virtualization. Something like this, for example.
Use AWS for my development virtual machines.
Then I came across a little company based out of San Diego called Antsle. Antsle builds virtualization appliances. What makes their product attractive to me versus buying a workstation or server or building my own is that:
The machines have no fan or other moving parts–they are completely silent. The case acts as a heat sink.
The machines are energy-efficient. The docs say mine will run at 45 watts.
They are built on Linux with standard virtualization technology (LXC and KVM) plus some additional optimizations from Antsle.
They are ready-to-go out-of-the-box, saving me the time and effort of building my own solution.
I really like using AWS, and I think for production workloads, no one, not even your own internal IT data center, can do it cheaper or more securely. Plus the breadth of their service offering is nuts. But for my modest developer needs, I’m pretty sure I’ll break even within a year, and that’s not counting the productivity gain of not having to wait for instances to spin up or having to fool with the complexity of the AWS console.
So, after that analysis, I was ready to buy. The biggest struggle was to decide which model to buy and whether or not to do any upgrades. I went for an Ultra, which has an 8-core 2.4 GHz Intel processor, 32 GB of ECC RAM and two Samsung EVO 850 1 TB SSD drives. The drives are mirrored so that’s 1 TB of space. I could have expanded the RAM to 64 GB and increased the storage up to 16 TB, but it was hard to justify the added expense based on my needs.
My Antsle arrived last week and I’ve been pretty happy with it so far. I’ve got a set of “base” images created so that I can easily instantiate new machines based on typical components and configuration. For example, I have an image for every recent Alfresco release. When I need to work on one for a client project or to help someone in the forums, I can just clone one of my base images and start it up. I can let it run as long as I want without worrying about cost, and then kill it or keep it around as needed.
Here is a summary of my experience, thus far:
No setup necessary. I plugged it in, started it up, and was starting up machines in minutes.
Creating machines from templates, cloning machines, taking snapshots, and startup/shutdown happens very quickly.
Templates and instantiated machines take up less space than I would have thought, which is great. So far, I’m glad I stuck with the base storage option.
I haven’t pegged the CPU yet, but I have seen it spike briefly to as high as 50%, and that was when I was only running a single VM. I continue to see brief spikes here and there, but as I won’t have too many machines under load at any given time so I’m not that worried about it yet.
Documentation seems thorough and helpful. The company has been really responsive and helpful so far as well. They responded to a minor billing issue quickly and resolved it without a fuss.
I noticed when you clone a machine that has a bridged network adapter, the MAC address doesn’t change. You have to drop and re-add the NIC if you want a new MAC address, otherwise DHCP will assign it the same IP address as the original machine. This isn’t a big deal once you know the behavior.
I had to change the vm.max_mem_map setting to make Elasticsearch happy, which is a typical setup task for Elastic. It took me a minute to realize that needs to be done on the Antsle host and applies to all guests–it cannot be done on the individual VM, at least for LXC.
There does not appear to be a way to tag or comment on virtual machines. Additionally, the name you assign to each image is fixed-length and fairly short. So I’m somewhat concerned that, as my library grows, I’ll start to lose track of what’s installed on which machine. AntMan, the management console, seems to be evolving fairly rapidly so maybe this will change in a future release.
I’ve also created a few videos if you want to see it in action.
This video shows an Ubuntu and a CentOS image being created and then configured for bridged networking.
This video shows how image templates work and gives you a little bit of a feel for the performance using a real-world app (in this case, Alfresco running on CentOS) while other machines are running simultaneously (one Mail/LDAP machine and a four-node Elastic cluster).
It has been far too long since our last Apache Chemistry cmislib release, but we finally managed to get one out. The new release, 0.6.0, features support for the browser binding as well as many fixes contributed by the community.
If you make no changes to your code the library will continue to use the Atom Pub binding, by default. But, the browser binding, which communicates with CMIS 1.1-compliant repositories using HTML forms and JSON, is often preferable because it may be more performant than the XML-based Atom Pub binding.
To use the new browser binding, import it, then pass it to the CmisClient constructor, like this:
from cmislib.browser.binding import BrowserBindingclient = CmisClient('http://localhost:8081/chemistry/browser',
'admin',
'admin',
binding=BrowserBinding())
From there everything works like it always has.
For more information, please see the docs. If you have issues, please file a Jira with as much detail as possible, including the vendor and version of the repository you are working with. And if you have a fix, include that in your Jira. Contributions are welcome!
I recently spent some time standing up a four-node Raspberry Pi cluster running Docker and Docker Swarm. I had no real practical reason to do this–it just sounded fun. And it was!
Docker is a technology that allows you to package your applications together with the operating system into a virtual machine, called a container, that can run anywhere. Docker Swarm establishes a cluster of hosts which can be used to run one or more Docker-based containers. You tell Docker Swarm which containers you want to run and how many of each and it takes care of allocating those containers to machines, provisioning the containers, starting them up and keeping them running in case of failure.
For example, suppose you have an application that is comprised of a web server, an application server, a database, and a key-value store. Docker can be used to package up each of those tiers into containers. The web server container has a thin operating system, the web server, and your front-end code. The application server has a thin operating system, the application server, and your business logic. And so on.
That alone is useful. Containers can run anywhere–local developer machines, on-prem physical hardware, virtualized hardware, or in the cloud. Because the applications and the operating system they run on are packaged together as containers I don’t have to worry about installing and configuring the infrastructure plus the code every time a new instance is needed. Instead I just fire up the containers.
With Docker Swarm I can say, “Here is a fleet of servers. Here are my containers that make up my stack. Make sure I always have 6 web servers, 3 app servers, 2 databases, and 3 key-value stores running at all times. I don’t care which of the servers you use to do that, just make it happen.” And Docker Swarm takes care of it.
This works surprisingly well on Raspberry Pi. Sure, you could do it on beefier hardware, but it’s pretty fun to do it with machines no bigger than a pack of cards. I used a mix of Raspberry Pi models: 1 2b+ and 3 model 3b’s, but I’ve also seen it done with Pi Zero’s, which are even smaller.
The examples I’ll reference in the links below do simple things like install a node-based RESTful service that keeps track of a counter stored in Redis. But once you do that, it is easy to see how you could apply the same technique to other problems.
If you want to try it yourself, here are some resources that I found helpful:
I already had a 2b+ sitting around so I used that with 3 model 3’s. The performance difference between the 2b and the 3b was significant, though, so if I do much more with it I will replace the model 2 with another model 3. My existing model 2b+ has a Sense HAT attached to it, which, among other things, gives me a nice 8×8 RGB LED matrix for displaying messages and status indicators.
When it is all put together, it looks like this:
Last year I used my Raspberry Pi as part of a hands-on class I gave to some elementary school students for Hour of Code. I haven’t settled on what I might do for them this year or whether or not that will leverage my new cluster, but it is handy to have Docker running on my Pi’s because I can set stuff up, tear it down, and relocate it much more easily.
My friend and colleague, Peter Löfgren, recently wrote a blog post on what he sees as the two possible strategies Alfresco could pursue. He describes the two approaches as follows:
Vertical: You try to get as many as possible Community installs be converted to paying Enterprise customers. Convert from the bottom and up if you so like.
Horizontal: You try to get as many as possible to run Alfresco, even if they run the free Community version. A fair share will always want commercial support to have a professional backing. A broad approach, where you get market presence and self-sustained marketing.
Peter argues that, to date, Alfresco has used a vertical approach, which is really about pushing Enterprise Edition and begrudgingly acknowledging that Community Edition is an acceptable alternative, only when the client can’t currently justify the expense of an Enterprise Edition license.
Peter observes that the vertical approach pits Alfresco Enterprise Edition squarely against Community Edition making it very tempting for Alfresco sales people to badmouth Community Edition, because they often see it as cannibalizing their revenue. I actually don’t see this happening much anymore–sales people know that denigrating Community Edition is counter-productive because customers are savvy enough to know it is the same software and a good portion of the sales team understands the bigger picture.
Before I go any further, I should refer you to a blog post I wrote about a year ago called, “The plain truth about Alfresco’s open source ethos“. In it, I argue that Alfresco’s marketing strategy isn’t the community’s concern, and that the company is basically a “normal” software company that won’t ever be the dogmatic open source company many of us wish it was.
But Peter brought it up and I like discussing such things, so I’ll ignore my own advice and provide my take on why I think Alfresco will continue to ignore the horizontal strategy and will continue to basically act like any other traditional software company…
Here’s my take
First, let’s compare Alfresco with another commercial open source company, Elastic. Elastic is the company behind the popular search engine Elasticsearch as well as a variety of related big data and analytics tools such as Logstash, Kibana, and Beats. Like Alfresco, Elastic makes money from support, and their incentive to get people to pay for support is to offer a set of products they make available only to paying customers. Unlike Alfresco, Elastic ships a single distribution of their products. For a given release of Elasticsearch, for example, there is no difference between what a paying and non-paying customer downloads and runs. It’s just that if you want some additional value-add on top of what’s freely-available, you have to pay.
So this is an example of a horizontal pursuit as Peter describes it. The reason it is working for Elastic, though, is that their offerings are much more horizontal than Alfresco’s. Elasticsearch is more popular and more widely used in all kinds of use cases. Their download stats are impressive and increasing steadily.
Alfresco, on the other hand, is niche software. It is quite narrowly focused on document management. Yes, there are a lot of use cases within that, but it isn’t something that you see embedded in all sorts of applications like you would a database, a workflow engine, or a search engine. I suspect download stats are flat or maybe even decreasing, although this is a bit of an apples/oranges comparison as the two products are in different phases of maturity and adoption.
The other issue is one of leadership. Elastic’s CEO, Steve Schuurman, exudes open source. He was a co-founder of SpringSource, for example. Both he and Shay Bannon, the creator of Elasticsearch, have said repeatedly that Elastic will always be open source and that they’ll never have an Enterprise-only distribution of their core software. That’s the kind of leadership I expect from a commercial open source company.
Contrast that with the current leadership at Alfresco. When former CEO John Powell announced his retirement, the board could have chosen someone with open source credibility like Elastic’s Steve Schuurman. Instead, they went with Doug Dennerline. He and his lieutenants have next to zero open source credibility or experience. It is clear they were brought on solely to take the company public. For them, open source is not a driving part of their worldview. Instead, their focus is simply to build a software company and take it public, employing whatever strategy gives them and their shareholders the biggest revenue numbers year-after-year. (I don’t mean to paint this in an overly-negative light–it is what it is. I’m just trying to point out the stark contrast in motivation and philosophy between the two leadership teams).
Unfortunately, a horizontal strategy does not necessarily equate to those kind of numbers. With Red Hat as the notable exception, it is hard to find a commercial open source company with financials that Doug, the board, and investors are looking for.
Do the math. Let’s assume there are 50,000 installs of Alfresco Community Edition. I have no reason to believe that is accurate–this is just an exercise. What kind of conversion rate would you expect? You’ll probably guess too high, forgetting that Alfresco is now very expensive, even for modest installations, and that the company is still working to add more differentiation in its paid offering compared to the free product. Let’s use 2%. So that’s 1,000 paying customers, which is roughly the number John Newton disclosed publicly in a keynote several years ago. It’s probably higher now, but remember that there is attrition we haven’t accounted for and those customers have to be earned year after year.
Now, what do you think the average sales price of Alfresco is across all of their paying customers? Again, just spit-balling, let’s say it is $100k annually. Multiply that times 1,000 and that’s “only” a company with $100 million in annual revenue. If you’re looking for a $1 billion IPO, that’s not enough. (If EMC sells Documentum to someone for 10x revenue I’ll have to update this post, but I think I’m pretty safe).
In a horizontal strategy, those are your levers: Total installs, conversion rate, attrition, average sales price. For example, using the horizontal approach, to increase revenue from $100 million to $300 million you would have to triple the number of Community Edition installs from 50,000 to 150,000. Alternatively, you could keep CE installs steady at 50,000 and instead triple your conversion rate from 2% to 6%. Which seems easier?
My bet is that rather than increasing total Community Edition installs, Alfresco will find it easier to increase the conversion rate by increasing differentiation between the two products, cutting attrition by implementing “customer success programs” and consulting, and continuing to put upward pressure on the average sales price by charging more for the core product and finding new paid add-ons to sell.
The horizontal approach Peter advocates may be the one we all wish would work, but I think that ship has sailed.
One of my clients came to me with a problem: Despite being a much-admired Fortune 500 company that leads its competitors in the travel industry in customer satisfaction and profitability, their web site, through which the vast majority of their revenues flow, was still mostly static. That by itself is not a huge problem, but they felt like they weren’t able to target content based on their customers’ needs and interests as well as they could with a more dynamic content engine.
It just so happened they were about to re-implement their site from mostly server-side to mostly client-side which is a huge undertaking. They figured that would be a pretty good time to add a dynamic content service to the mix, so they called me.
From Static to Dynamic
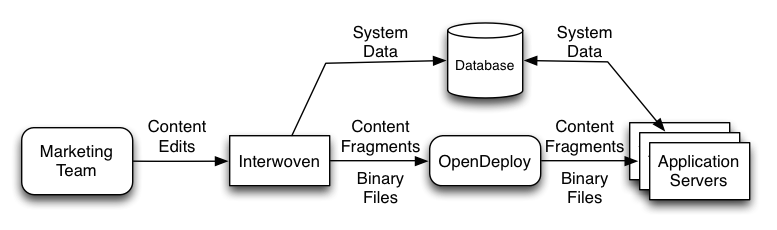
The diagram below depicts the high-level setup before the introduction of the content service.
This is pretty standard for sites like this. The Marketing Team edits content in a Content Management System (CMS), which in this case is Interwoven. Through various processes, binary files (mostly images), system data (things like lists of destinations and hotels), and content fragments are published out of Interwoven to destinations accessible by the e-commerce application.
A content fragment is literally a piece of content. It might be a promotion of some sort. Or it could be some text that gets used as part of a banner. The challenge using this setup is that content fragments are static files that live on the file system. If you want to show a different fragment based on something you know about the user you have to generate every permutation you might want ahead-of-time, publish them all, then use logic in the application to decide which one to use.
One obvious way to address this is to publish content fragments in a relational database and then code the front-end app to query for the right content. That wasn’t appropriate here for a few reasons:
The front-end is being migrated to a collection of Single Page Applications (SPA’s) written in JavaScript. It’s easier for those pages to call a RESTful API to get JSON back. Yes, you could still do that with a relational database and a service tier, but the client was looking for something a little more JSON-native.
The structure of the content changes over time. We wanted to be able to accept any kind of content fragment the Marketing Team or SPA developers could think of and not have to worry about migrating database schemas.
The anticipated style of queries needed to find appropriate content fragments was more like what you’d expect from a search engine and less like what you might put in a SQL query–we needed to be able to say, “Here is some context, now return the most appropriate set of content fragments for the situation,” and be able to use relevancy scoring to help determine what comes back.
So relational databases were ruled out in favor of document-oriented NoSQL repositories. Ultimately, Elasticsearch was selected because of its ease of clustering, high performance, unified REST API, availability of commercial support, and add-ons such as Shield, Marvel, and Watcher that make it easier to integrate with the rest of the enterprise.
Introduction of a Content Delivery Service
The first thing we did was stand up an Elasticsearch cluster, load some test data, and beat the heck out of it (see “Using JMeter to Test Elasticsearch“). Once we were satisfied it would be able to handle more than the expected load we moved on to the service.
The Content Delivery Service sits between Elasticsearch and the front-end applications. Its purpose is to abstract away Elasticsearch specifics and to protect the cluster by providing a simple, read-only REST API. It also enforces some light business logic such as making sure that only content that is currently effective according to its publication and expiration date is returned.
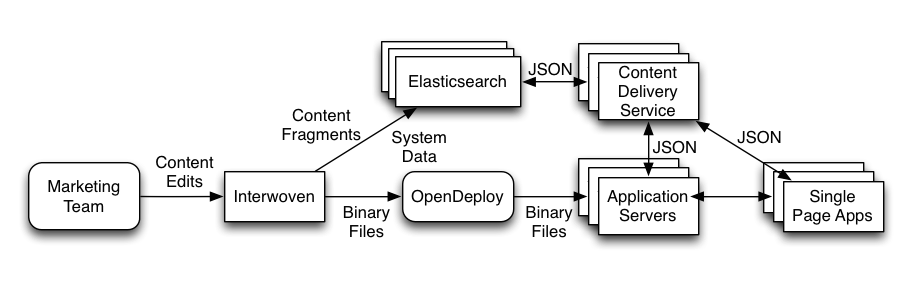
The diagram below shows the content infrastructure augmented with Elasticsearch and the content delivery service.
As seen in the diagram, Interwoven is still the source of record and the primary way Marketing manages their content. But now, content fragments and system data are published to Elasticsearch. The front-end Single Page Apps ask the Content Delivery Service for content based on some set of context. The content is returned as a collection of JSON objects. The SPAs then take those objects and format them as needed.
Content Objects are Pure Content
A key concept worth emphasizing is that a content object is pure content. It contains no markup. It might have some properties that describe how it is expected to be used, but it is completely lacking in implementation. This has several benefits:
Content objects returned by the Content Delivery Service can be used across any and all channels (such as mobile) rather than being specific to a single channel (such as web).
Within a given channel the same object can have many different presentations.
Responsibilities are cleanly separated: The content service provides content. The front-end applications style and present the content for consumption.
This was a bit of a departure from how things used to be done. In the bad old days presentation was always getting mixed up with content which severely limits reuse.
Micro-services Provide Administrative Features
I mentioned earlier that the Content Delivery Service is read-only. And in my previous diagram I showed Interwoven talking directly to the Elasticsearch cluster. In reality, we don’t let anyone talk directly to the Elasticsearch cluster. Instead, all writes have to go through the Content Management Service. This ensures that we know exactly what is going into the cluster and who is putting it there.
The other role the Content Management Service plays is JSON validation. When new types of content objects are developed we use JSON Schema to codify the structure. When a person or system posts a content object to the Content Management Service, the service validates the object against its JSON Schema before storing it in Elasticsearch.
In addition to the Content Management Service we also implemented a Scheduled Job Service. As the name suggests, it is used to perform administrative tasks on a schedule. For instance, maybe content needs to be reindexed from one cluster to another in a lower environment. Or maybe content needs to be fetched from a third-party and written to the cluster. The Job Service is able to talk to either the Content Management Service or Elasticsearch directly, depending on the task it needs to execute.
All of the administrative services are independently deployed web applications that sit behind an API Gateway. The Gateway leverages the Netflix Zuul Proxy. It is responsible for authenticating against LDAP and creating a shared session in redis. It gives the content admin team a single URL to hit and isolates authentication logic in a single place.
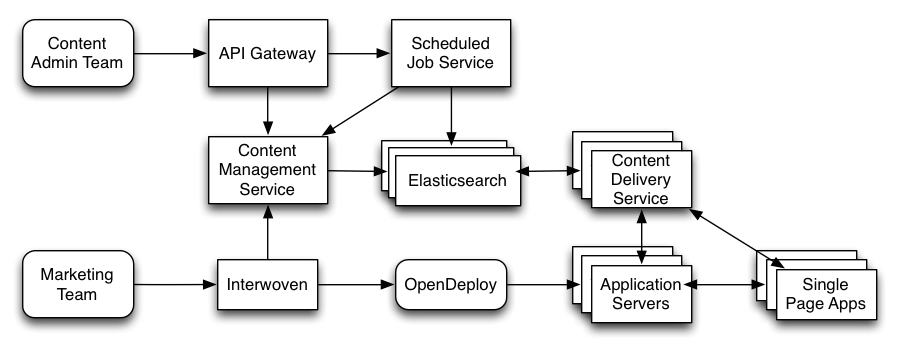
The diagram below shows the fully-realized picture.
A few key components aren’t on the diagram. We use Shield to protect the Elasticsearch cluster. Shield also makes it easy to configure SSL for node-to-node communication and provides out-of-the-box LDAP integration. With Shield we can map LDAP groups to roles and then grant roles various privileges on our Elasticsearch cluster and its indices.
We use Watcher to monitor cluster health and job failures that may happen in the Scheduled Job Service. The client has their own enterprise alerting and monitoring solution, but Watcher gives the content management team a flexible, powerful tool for keeping track of things at a level that is probably more granular than what the enterprise ops team cares about.
Ready for the Future
With Elasticsearch and a few relatively small services on top of that, this travel giant now has what it needs to provide its customers with a more customized online experience. Content can be targeted to the users it is most appropriate for using any kind of context the Marketing team can come up with. As the front-end commerce app evolves, new types of content objects can be added easily and be served to the front-end with no schema or service changes required. And it’s all built on commercially-supported open source software.
Almost all of my client work is remote. For many projects, that means chat is an essential communication tool. When you and your team essentially live in a chat window it’s nice when your tools can participate in the conversation. Luckily, it’s pretty easy to wire this up. Let me show you how I did it for a recent Elasticsearch project.
Openfire: An open source chat server
Today, hosted chat services like Slack and HipChat get all of the attention. The approach I outline in this blog post will work with those tools too, but on this particular project we’re running an open source chat server on-prem called Openfire. Openfire has been around for a long time. I like it because it is open source, easy to install, and will run anywhere you can run Java.
Because it implements an open protocol called XMPP (aka Jabber) there are a variety of chat clients that will work with it. Openfire ships a web-based client called Spark and some of my teammates use that, but most of the time I use Adium on my Mac.
If you need help installing Openfire, take a look at the docs.
Inbound and outbound integration with Elasticsearch
Once your chat solution is working, it’s time to integrate it with Elasticsearch. For my requirements I needed two “directions” for this integration. First, I wanted to be able interrogate one or more of my Elasticsearch clusters from within chat. This “outbound” integration requires a “bot”. There are many open source bots to choose from and examples of bot scripts working with Elasticsearch. I’ll cover both shortly.
The other direction I needed was “inbound”–I wanted my Elasticsearch cluster to be able to tell the chat server when something is wrong with the cluster. This requires something to monitor the health of the cluster (we use Watcher, a paid add-on from Elastic) and a web hook that can use the chat server API to send messages.
Let me cover the outbound implementation–the bot–first. Then I’ll talk about Watcher and the web hook which make up the inbound implementation.
Hubot: An open source chat bot from Github
There are a number of chat bots out there. I went with Hubot from Github. Hubot is based on Node.js. Hubot scripts are written in Coffeescript. However, if you are new to Node or Coffeescript there are plenty of examples out there so don’t let that stop you from using Hubot.
I used this blog post to get Hubot working. However, there were a few gotchas I should point out:
I had to use an old version of node.js (0.10.23). The newer version was having a lot of trouble with one of its dependencies and I got tired of fooling with it.
The blog post lists some Linux dependencies you need to install, but it leaves one out that’s critical: libicu. On Centos this is libicu-devel and on Ubuntu it is libicu-dev.
The blog post specifies some environment variables that need to be set. If you are running Hubot with Openfire, the HUBOT_XMPP_ROOMS variable needs to be set to the fully-qualified conference room name. For example, if the Hubot username is “hubot” running on a host named “grumpy” the variable should be set to hubot@conference.grumpy.
You may have to set HUBOT_XMPP_HOST to the hostname of your Openfire server.
Other than that, you should be able to use that blog post to get Hubot and Openfire working.
Hubot and Elasticsearch
There are Hubot scripts that do all sorts of stuff. One of the fun things about adding a bot to your chatroom is to have it do something silly. Maybe every time someone uses the word “Dude” the bot throws out a quote from the Big Lebowski, for example. So you’ll see lots of stuff like that. But there are also more useful examples out there. Here is the one I started with. The hubot-elasticsearch script knows how to use the Elasticsearch API to spit out information about nodes, indices, allocation, and settings. And it allows you to alias your clusters so you don’t have to constantly tell the bot what your URL endpoints are.
Out-of-the-box, the hubot-elasticsearch project is not compatible with Shield, but it’s a decent start. I made a small tweak to get it to work with Watcher, which I’ll cover next.
Watcher: Monitoring and Alerting for Elasticsearch
This particular client is a paying customer of Elastic, which means they are entitled to paid-only add-ons such as Shield (secures the cluster) and Watcher (for monitoring and alerting).
Watcher is pretty handy and we’re glad to have it, but if you aren’t able to use it for some reason, writing your own tool for running tasks on a schedule isn’t too tough. I wrote something similar using Spring MVC and Quartz, for example. You just need something that will periodically interrogate the cluster and then take some action based on some condition. But if you are an Elastic customer there’s no need to build it. The rest of the post assumes that’s the case.
I’ll let you read the Watcher docs to learn more, but at a high level, a watch consists of a trigger, an input, a condition, and an action. The trigger is the schedule. The input might be an Elasticsearch query or the response from some random HTTP endpoint. The condition looks at the input and then decides whether or not action is needed. The action taken might be to send an email, create some data in Elasticsearch, or invoke a web hook.
For my needs, the web hook action is perfect–if one of my watch conditions is met, like maybe something goes wrong with my cluster and the cluster state goes to red, Watcher will invoke my web hook which will post a message in the chat room. Here’s what the action part of my watch definition looks like:
"actions": {
"notify_chat": {
"webhook": {
"method": "POST",
"host": "localhost",
"port": 8008,
"path": "/chat",
"headers": {
"Content-Type": "application/json"
},
"body": "cluster_health alert: Someone needs to look at the DEV cluster. It appears to be in a RED state."
}
}
}
Watcher can have any number of actions listed for a given watch. In this case, I’m using a single “webhook” action called “notify_chat” that does a POST to a URL running on port 8008. That URL could be anything, and it can include basic authentication.
Web Hook: Spring Boot, Spring MVC, and Smack
I’ve been using Spring Boot lately when I need to knock out a quick RESTful API. In this case, I just needed something to listen to the “/chat” end point. When it is called, the code grabs the message posted to it and uses the Smack API to connect to the chat room and post the message. This webapp is probably less than 10 lines of code and Spring Boot packages it up nicely for me.
Watcher can throttle or suppress actions based on a time period (“Don’t tell me about this condition again for 5 minutes,” for example) or explicit acknowledgement. If a watch is triggered that uses explicit acknowledgement, I want to be able to acknowledge that from within chat. You already saw that the Elasticsearch Hubot script can talk to the cluster. It’s pretty easy to tweak the script to allow Watcher acknowledgement.
First, I added a function called “ackWatch” that actually does the work of acknowledging the watch:
Then, I added the regular expression that the bot should be listening for:
robot.hear /elasticsearch ack (.*) (.*)/i, (msg) ->
if msg.message.user.id is robot.name
return
ackWatch msg, msg.match[1], msg.match[2], (text) ->
msg.send text
With that in place, any user in the chat room can acknowledge a watch by typing, “hubot: elasticsearch ack some_watch some_alias” where some_watch is the ID of a watch and some_alias is the nickname for the cluster you’re talking about (like “dev”, “qa”, or “prod”, for example).
Putting it all together: A short demo
With all of this in place, my Elasticsearch clusters can tell the team when something interesting is going on and the team can acknowledge that alert and do preliminary investigation by interrogating the cluster, all from the comfort of their chat window.
The video below shows this working. In it, I create a simple watch that invokes a web hook to post a message to the chat room when a watch condition is met.
The demo uses a simple example where the alert is triggered when the test index is a certain size. But you could easily wire up any watch to the same action, such as when your cluster state goes red or when CPU or RAM reach a certain threshold.
This was relatively simple to put together, but hopefully you can see how you could build on this to automate all kinds of things related to monitoring, alerting, and administration of your Elasticsearch cluster from chat.
Pick a commercial open source software product that’s important to you. Now imagine that there’s been a global zombie attack. Fortunately, after much heroics and stylized cinematic violence, the attack is eventually thwarted. Unfortunately, it wasn’t soon enough. Everyone who receives a paycheck from the company behind your favorite commercial open source company is now a zombie in the steadfast pursuit of acquiring brains for food–they could care less about your sev one support ticket. The question is this: Can the open source software project survive without its commercial backer?
My blog readership consists of multiple audiences. For some of you, the question posed is interesting because your company depends on that software to run its business. For you, this is a “sole source supplier” problem with the primary concern being: If the software vendor goes away, is there another place I can get the same software?
Some of you are like me–you provide professional services around commercial open source software. The commercial company produces the software you deliver to your clients but may also provide other types of assistance such as marketing, business development, and training.
Still other readers might be classified as “community members” who give time and resources toward the project. Members of the first two groups are often members of this group as well. It is this group–the community–that becomes critical in answering this survivability question as we shall soon see.
Okay, so back to the scenario. Zombies attack. Zombies subdued. Sadly, all of the employees of our commercial open source software vendor are no more. Why is the question of survivability even a question? Remember, we are talking about open source software with a primary commercial backer. Your organic open source projects are safe from zombie attacks, for the most part, because there is no single company responsible for its development. For organic open source projects with a large, healthy community, the load of building and maintaining software is distributed across potentially hundreds or thousands of individuals employed by many different companies. Commercial open source, on the other hand, has a single company that pumps significant dollars into engineering, research and development, sales, and marketing. If that company goes away, there’s a clear risk to the project. Stakeholders need to understand this risk.
For the rest of this analysis, I’m going to ignore the very real investments commercial open source vendors make around marketing, business development, community management, and training. These things matter, of course, but they don’t matter at all unless you ship code. As the smoke clears from the zombie attack, the single most important thing facing the surviving stakeholders is getting out the next release.
Suppose our zombie-stricken company sold support for what was already an extremely successful open source project. There are many people who regularly make very significant contributions to the code base and documentation. There are lots of people answering questions in forums and on IRC. That healthy community means there is a viable population of non-zombies who will obviously mourn the loss of their former collaborators, but will no doubt bravely carry on.
Now, instead, imagine a commercial vendor who is really open source in license only–they lack a community entirely. There are exactly zero people outside of the company who know anything at all about where to get the code and how to build and test it, let alone the intricate details of how it works. It’s clear this project is doomed. Maybe someone would fork the code base and start a new company but that would be tough. Unlike what MariaDb did after the Oracle-MySQL acquisition, our scenario doesn’t allow a new company to bootstrap with experienced founders or engineers, at least those who were employed by the vendor at the time of the zombie attack.
From looking at these two extreme ends of the spectrum it is clear that the thing that allows the project to continue is the viability of the project as an independent open source project and that depends on the health and makeup of the community.
To answer this question–whether or not a commercial open source project could operate as an independent organic open source project–there are several aspects of the current community to assess:
Pre-commercial open source success. If the software project was a successful organic open source project before the commercial company appeared, this is a good indicator that if that company were to go away, the software project would survive.
Governance model. Is the software and associated trademarks under the control of an independent foundation? If so, that’s good–a lot of the details and processes will already be taken care of. Formal governance of this sort is designed around ensuring viability independent of a single commercial backer.
Number of external committers. How many committers are employed by the commercial company? If the answer is 100% that’s bad for survivability. In our scenario anyone working for the company is now a zombie which means there will be fewer experienced people to work on the next release.
Number of external contributions. What kind of contributions have typically come from the community? If it is low volume or mostly insignificant patches, this is another negative indicator. If the project stands a chance of survival post zombie attack it needs significant activity from independent contributors because that provides a population of people who are familiar with the technical details of the product.
Install base. A product installed in a large number of big companies would be ideal but even a few large “anchor” companies would be sufficient. The surviving community will need to pool its resources to move the project forward. If it is strategic to stakeholders with deep pockets, those stakeholders may be willing to invest in the software’s future.
Product complexity. The simpler, the better. When a product gets complex, its engineering team starts to specialize. A large community could do that too, but if the product is complex and the surviving community is too small, there may not be enough people who can go deep enough on every part of the system to maintain the entire thing. A complex product also requires more resources to test and build.
Upstream dependencies. If the product is a relatively thin veneer on a handful of well-known upstream dependencies, that’s good. It means you might be able to depend on some of those upstream communities for help. However if the system is complex and has a lot of smaller dependencies, it means the surviving community has a lot to learn and the upstream communities may lack the resources to be of much help.
Downstream dependencies. If the software is used by many other projects downstream, that’s a good thing because it significantly increases the number of people interested in keeping the project alive.
Company diaspora. How much turnover has there been over the life of this company’s engineering department? Low turnover means there will be fewer people in the market who know the deep dark secrets of the code base.
Community makeup. This is closely related to the “external contributions” aspect. If the community is mostly “power users” that’s a problem for survivability. What you need is a community that has a significant number of individuals who are passionate and technical enough to dedicate time and resources to moving the software forward. It obviously helps if the software is strategic to their employers.
You might assess your favorite commercial open source software and realize that it isn’t viable without commercial backing. That doesn’t mean it’s a bad company or a bad product. What it does mean depends on your perspective:
If you depend on the software for your business…
And you are evaluating the software for purchase, you cannot give “availability of source code” a much higher score against other alternatives because one of the benefits you derive from that–the ability to continue forward should the company go away–is less likely to be realized. (see “Why Clients Choose Open Source”).
And you already have the software installed, have a backup plan in mind should something happen to the vendor, just like you would a proprietary vendor. If you deem a major event to be likely, consider moving to an alternative now.
If you are part of the commercial open source software project’s community…
Push for changes in the aspects identified above that would make the project more viable as an independent project. Realize, however, that not all vendors are enlightened (or empowered) enough to execute these changes.
Be okay with the fact that you are dedicating time and energy to something that depends mostly (or entirely) on its commercial backing. This means not getting bent out of shape when the commercial company does something to further its commercial interests. Or don’t be okay with it and move on.
Assess your zombie attack survivability as a community and identify initiatives that address areas of weakness.
If you are the commercial open source software vendor…
Be careful how you market your open source-ness. If your software fails the zombie survivability test but you tout open source as a major advantage, your marketing message may ring flat.
Be open to ideas that could give your software the ability to outlive you. This makes it more attractive to customers and community members alike. It makes your open source claim more genuine.
Obviously the specific threat of a zombie attack is far-fetched. But the risk of a commercial open source company being acquired, folding, or radically shifting their business model is quite real. Just because “commercial open source” has “open source” in it, does not magically give it a vibrant community that can fulfill the vital engineering and quality assurance role that the commercial company often provides. Even a vibrant community may lack the proper make-up to step in should it need to.
Regardless of which role you play, if you are a stakeholder in a commercial open source software product, it is important you assess this risk and have a plan should the need arise.
Jeff and Justin zip-lining during Mozilla Work Week in WhistlerI’m in Orlando for Mozilla Work Week, which is an event that happens a couple of times a year aimed at bringing the organization’s far-flung employees and contributors together to collaborate on projects.
But I’m not here because of my own code contributions–I’m here as a chaperone. My 17 year-old son, Justin, earned his third trip to Work Week as an invited guest by dedicating time and code towards Mozilla’s mission of a free and open web.
Mozilla has thousands of contributors worldwide. Only a handful get invited to Work Week, so this is a Proud Open Source Dad Moment® for me, but I thought I’d share his story in the off chance that it motivates you or your kids to participate.
A few years ago Justin asked how he could get more involved in an open source project. He had just finished Google Code-In, which matches up High School students with open source projects. It’s a cool program, but it only lasts a few months and the projects he contributed to were somewhat esoteric. He was looking for two things in a project: it needed to mean something to him personally so that it would hold his interest and it needed to offer a technical ramp that would help grow his skills.
I told him to take a look at Mozilla. My own experience contributing to Mozilla was that they were good at getting contributors aligned with projects based on their skills and interests (check out their signup page).
At the time, Justin was new to coding. I had taught him Python but he wasn’t feeling confident enough to put those skills to use on a public project. So he started reviewing and editing technical documentation. This was a perfect place to start because it offered a chance to learn more about the culture of the organization and its tools and processes while also being exposed to the dizzying array of products, acronyms, and technologies in play at Mozilla.
Then one day I walked into Justin’s room. He was hammering away at his laptop. “What are you working on?”, I asked. Without looking up he replied, “I’m writing some automated test scripts in Python using Selenium.” He was clearly “in the zone” so I just said, “Oh, cool,” and headed back down the hall, but I was pretty pumped–my kid was committing code.
Justin had found his way onto the Web Quality Assurance team. They make sure all of Mozilla’s sites are running correctly. This led to a cool father-son moment. I had been contributing some code to Mozillians, which is one of the sites Justin’s Web QA team was responsible for. Justin came to me with a problem: He could improve the efficiency of his tests if a small change was made to one of the site’s pages. He was reluctant to make the change but he knew I could do it quickly, so I did, and we ended up spending an afternoon hanging out in his room, squashing bugs and testing.
As his confidence and skills grew, so did his influence and responsibilities within Mozilla. He became a “vouched” Mozillian and, later, was added to some of the internal systems reserved for trusted contributors, and was ultimately granted the ability to commit code directly to Web QA’s projects. He participated on as many of the team’s online meetings as his school schedule would allow, began mentoring other contributors, and was given his own project to run.
This gradual increase in trust and recognition that occurs over time as a contributor spends time with a project is a key part of what makes open source work. He and I had discussed “open source” as a concept a lot, but it didn’t really sink in until he became part of it, and it has been wonderful to watch.
Something that’s been particularly instructive is how Mozilla treats its contributors. During a family vacation to San Francisco we toured both of Mozilla’s offices. Every person we were introduced to stopped what they were doing and thanked us. We felt special and appreciated.
This attention extends to code contributions. When I made my first contribution I worked with a mentor of sorts who helped me understand the workflow and coding standards for the project. If he didn’t hear from me in a while he’d shoot me a note to see if I still had time to work on the project. His continued interest made me feel like my contributions mattered, even if they were small.
Justin’s mentor went even further, offering career advice and making personal introductions. He’s even been helping Justin find internship opportunities.
When I think about everything his Mozilla experience has given him, I’m amazed. Of course he’s been apply to apply his coding skills in real world applications. But there is also a set of important technical skills that are hard to teach in a classroom, like how to be productive in a multi-developer git workflow. Perhaps more crucial are the softer skills, like how to give constructive feedback to teammates or how to pitch an idea. And the cool thing is that while he’s soaking up all of this, he’s helping further Mozilla’s mission, which is something both of us believe in.
If you know someone who believes in a free and open web, and they have the time and interest to get involved and to stick with it, encourage them to signup and get involved. There’s plenty to do for all skill levels and interests.

 I love virtual machines and containers because they make it easy to isolate the applications and dependencies I’m using for a particular project. Tools like Docker, Virtualbox, and vagrant are indispensable for most of my projects and I’m still using those, but in this post I’ll describe a product called Antsle which has given me additional flexibility and has freed up some local resources.
I love virtual machines and containers because they make it easy to isolate the applications and dependencies I’m using for a particular project. Tools like Docker, Virtualbox, and vagrant are indispensable for most of my projects and I’m still using those, but in this post I’ll describe a product called Antsle which has given me additional flexibility and has freed up some local resources.