Jeff Potts' personal blog about Alfresco, content management, BPM, search, and other stuff
Category: Elasticsearch
Elasticsearch is an open source, highly-scalable search engine and JSON document repository. It has a REST API and a number of client libraries that can be used to integrate it into any application that needs fast, flexible search and aggregation.
Earlier this month, Google announced that it is getting out of the search appliance business. According to this article by Fortune, Google told its partners they could renew existing Google Search Appliance (GSA) customers through 2017 but no new hardware would be sold.
I have multiple clients running GSA for Enterprise Search and their experiences have been mixed. Clearly, the plug-and-play nature of a turnkey appliance was attractive. But, of course, the other side of that coin is the potential set of limitations that an appliance places on you, whether that’s in terms of cost/license, capacity, or features.
GSA customers have time to figure out their migration path. Google says they are working on a cloud-based alternative. But maybe it’s time to take a step back and consider your options.
Something big has happened since the last time you looked at Enterprise Search: It’s called Elasticsearch. The commercially-supported open source software builds on the rock solid foundation of the well-known Apache Lucene by baking in clustering and a comprehensive API out-of-the-box.
Adoption has been swift. At last year’s Elasticon conference, the company reported 20 million downloads. At this year’s conference the company announced they had hit 50 million downloads across all of their products.
Deployment options
If you want to self-support, you can set up a cluster on-prem and scale it as big as you need it for the cost of your time and some hardware. If you need commercial support you can get it from Elastic.
If a cloud-based solution is attractive to you there are several options:
Elastic has its own cloud offering called Elastic Cloud (formerly called “Found”).
Amazon offers its own hosted Elasticsearch offering called Amazon ES.
And you can always just grab some virtual machines on your cloud provider of choice and install and run your own cluster.
The Elastic Stack provides the core search platform and a host of other tools, but it does not provide a web crawler. You’ll probably want to use Scrapy, StormCrawler, or Nutch for this, all of which are freely available as open source software.
Beyond crawlers there are a ton of different ways to get content indexed into Elasticsearch. Beats and Logstash are two Elastic products that can be used to pump data into the cluster. If you have to write your own integration, the API is fairly straightforward and is available for a number of languages as well as anything that can speak REST.
You’ll be shocked at how quickly you can stand up an Elasticsearch cluster. Where you’ll likely spend more time is on production-izing your setup and tuning for relevancy (take a look at the Relevant Search book from Manning).
Your GSA was only ever going to be good at one thing–providing keyword search for your internal documents. Elastic gives you that and so much more. You might start out using it to replace your GSA-based Enterprise Search but you’ll soon figure out that it can be used for all kinds of interesting things.
Elasticon 2016 is just around the corner. The annual conference covering all things Elastic is happening February 17 – 19 in San Francisco.
Last year, the buzz was all about Elasticsearch 2.0. Attendees learned a lot about what to expect with that release. But my favorites were the sessions that covered real world implementations. Some of these included:
How the U.S. Geological Survey uses Elasticsearch to be notified of earthquakes as they happen by monitoring and analyzing social media.
Verizon’s best practices around scalability–they have 128 nodes indexing 10 billion documents per day.
Goldman Sachs was another big one–at that time they were running 700 nodes.
Interesting case studies from Wikimedia, Quizlet, Zen Desk.
Focus on analysis challenges from the team that runs Elasticsearch to provide web search for 1500 dot gov web sites such as the NIH and the U.S. Army.
Beyond informative sessions, you can learn a lot in the hallway track. At last year’s conference there were 1300 attendees from 32 different countries. I met people from both ends of the business spectrum doing all sorts of different things with Elasticsearch and the rest of the ELK stack.
This year’s agenda looks pretty interesting. I’m looking forward to the roadmap sessions, of course, but it’s the sessions from folks like Thomson Reuters, Yammer, HotelTonight, Eventbrite, Etsy, The New York Times, and Adobe that will probably give me the most bang for my buck. It only takes a few key insights here and there to pay for the entire trip.
Amazingly, this year’s conference has not sold out yet. Grab a spot and join us. Today is the last day for the discounted rate.
One of my clients came to me with a problem: Despite being a much-admired Fortune 500 company that leads its competitors in the travel industry in customer satisfaction and profitability, their web site, through which the vast majority of their revenues flow, was still mostly static. That by itself is not a huge problem, but they felt like they weren’t able to target content based on their customers’ needs and interests as well as they could with a more dynamic content engine.
It just so happened they were about to re-implement their site from mostly server-side to mostly client-side which is a huge undertaking. They figured that would be a pretty good time to add a dynamic content service to the mix, so they called me.
From Static to Dynamic
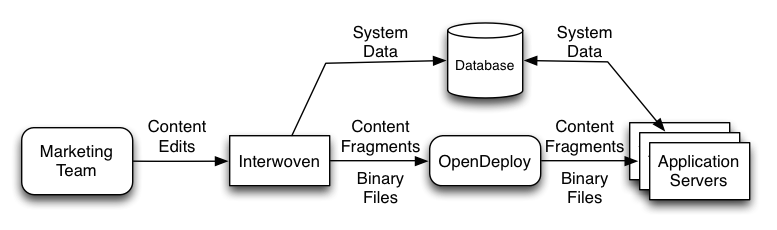
The diagram below depicts the high-level setup before the introduction of the content service.
This is pretty standard for sites like this. The Marketing Team edits content in a Content Management System (CMS), which in this case is Interwoven. Through various processes, binary files (mostly images), system data (things like lists of destinations and hotels), and content fragments are published out of Interwoven to destinations accessible by the e-commerce application.
A content fragment is literally a piece of content. It might be a promotion of some sort. Or it could be some text that gets used as part of a banner. The challenge using this setup is that content fragments are static files that live on the file system. If you want to show a different fragment based on something you know about the user you have to generate every permutation you might want ahead-of-time, publish them all, then use logic in the application to decide which one to use.
One obvious way to address this is to publish content fragments in a relational database and then code the front-end app to query for the right content. That wasn’t appropriate here for a few reasons:
The front-end is being migrated to a collection of Single Page Applications (SPA’s) written in JavaScript. It’s easier for those pages to call a RESTful API to get JSON back. Yes, you could still do that with a relational database and a service tier, but the client was looking for something a little more JSON-native.
The structure of the content changes over time. We wanted to be able to accept any kind of content fragment the Marketing Team or SPA developers could think of and not have to worry about migrating database schemas.
The anticipated style of queries needed to find appropriate content fragments was more like what you’d expect from a search engine and less like what you might put in a SQL query–we needed to be able to say, “Here is some context, now return the most appropriate set of content fragments for the situation,” and be able to use relevancy scoring to help determine what comes back.
So relational databases were ruled out in favor of document-oriented NoSQL repositories. Ultimately, Elasticsearch was selected because of its ease of clustering, high performance, unified REST API, availability of commercial support, and add-ons such as Shield, Marvel, and Watcher that make it easier to integrate with the rest of the enterprise.
Introduction of a Content Delivery Service
The first thing we did was stand up an Elasticsearch cluster, load some test data, and beat the heck out of it (see “Using JMeter to Test Elasticsearch“). Once we were satisfied it would be able to handle more than the expected load we moved on to the service.
The Content Delivery Service sits between Elasticsearch and the front-end applications. Its purpose is to abstract away Elasticsearch specifics and to protect the cluster by providing a simple, read-only REST API. It also enforces some light business logic such as making sure that only content that is currently effective according to its publication and expiration date is returned.
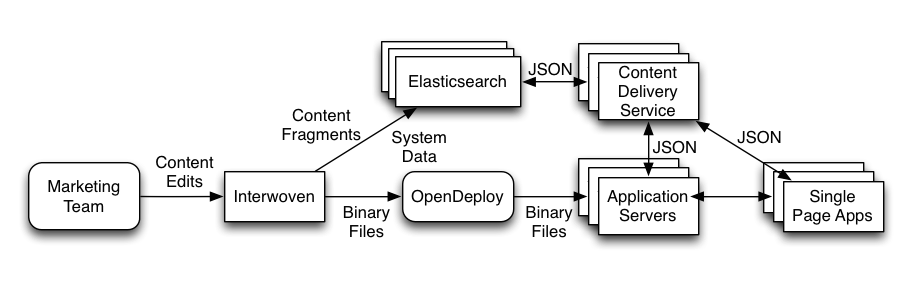
The diagram below shows the content infrastructure augmented with Elasticsearch and the content delivery service.
As seen in the diagram, Interwoven is still the source of record and the primary way Marketing manages their content. But now, content fragments and system data are published to Elasticsearch. The front-end Single Page Apps ask the Content Delivery Service for content based on some set of context. The content is returned as a collection of JSON objects. The SPAs then take those objects and format them as needed.
Content Objects are Pure Content
A key concept worth emphasizing is that a content object is pure content. It contains no markup. It might have some properties that describe how it is expected to be used, but it is completely lacking in implementation. This has several benefits:
Content objects returned by the Content Delivery Service can be used across any and all channels (such as mobile) rather than being specific to a single channel (such as web).
Within a given channel the same object can have many different presentations.
Responsibilities are cleanly separated: The content service provides content. The front-end applications style and present the content for consumption.
This was a bit of a departure from how things used to be done. In the bad old days presentation was always getting mixed up with content which severely limits reuse.
Micro-services Provide Administrative Features
I mentioned earlier that the Content Delivery Service is read-only. And in my previous diagram I showed Interwoven talking directly to the Elasticsearch cluster. In reality, we don’t let anyone talk directly to the Elasticsearch cluster. Instead, all writes have to go through the Content Management Service. This ensures that we know exactly what is going into the cluster and who is putting it there.
The other role the Content Management Service plays is JSON validation. When new types of content objects are developed we use JSON Schema to codify the structure. When a person or system posts a content object to the Content Management Service, the service validates the object against its JSON Schema before storing it in Elasticsearch.
In addition to the Content Management Service we also implemented a Scheduled Job Service. As the name suggests, it is used to perform administrative tasks on a schedule. For instance, maybe content needs to be reindexed from one cluster to another in a lower environment. Or maybe content needs to be fetched from a third-party and written to the cluster. The Job Service is able to talk to either the Content Management Service or Elasticsearch directly, depending on the task it needs to execute.
All of the administrative services are independently deployed web applications that sit behind an API Gateway. The Gateway leverages the Netflix Zuul Proxy. It is responsible for authenticating against LDAP and creating a shared session in redis. It gives the content admin team a single URL to hit and isolates authentication logic in a single place.
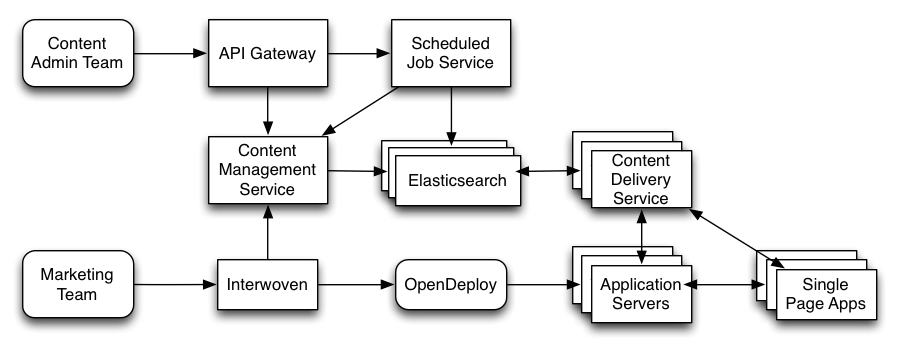
The diagram below shows the fully-realized picture.
A few key components aren’t on the diagram. We use Shield to protect the Elasticsearch cluster. Shield also makes it easy to configure SSL for node-to-node communication and provides out-of-the-box LDAP integration. With Shield we can map LDAP groups to roles and then grant roles various privileges on our Elasticsearch cluster and its indices.
We use Watcher to monitor cluster health and job failures that may happen in the Scheduled Job Service. The client has their own enterprise alerting and monitoring solution, but Watcher gives the content management team a flexible, powerful tool for keeping track of things at a level that is probably more granular than what the enterprise ops team cares about.
Ready for the Future
With Elasticsearch and a few relatively small services on top of that, this travel giant now has what it needs to provide its customers with a more customized online experience. Content can be targeted to the users it is most appropriate for using any kind of context the Marketing team can come up with. As the front-end commerce app evolves, new types of content objects can be added easily and be served to the front-end with no schema or service changes required. And it’s all built on commercially-supported open source software.
I stumbled onto Elasticsearch’s search templates feature on my last project and it turned out to be really useful. I remember being surprised I hadn’t seen it mentioned anywhere. I’ve asked around at the last couple of meetups I’ve attended and it turns out many people don’t know about search templates, so I thought it might make a good post.
I’m going to give some context as to why this feature was useful, then I’ll show you how to use it. If you don’t want or need the context, feel free to skip to the next section.
Context: Real world use case for search templates
For this particular project we were using Elasticsearch as a content service. A set of front-end Single Page Applications (SPAs) query the content service. The content service returns content objects as JSON that match some criteria. Components in the SPAs format the objects as needed.
The content service is a Java-based API that sits between the SPAs and Elasticsearch. The API abstracts the Elasticsearch details and adds some business logic regarding which content to return beyond simply matching the parameters specified by the front-end.
A simple example of one type of business logic the API adds is publish date and expiration date handling. All of our JSON objects in Elasticsearch have a publish date and some have an expiration date. When the front-end asks the API for content, we only want to return content that is current–in other words the current date has to be greater than or equal to the publish date and less than the expiration date if an expiration date is set.
If you leave this up to the front-end, and if the API is open, then anyone can get any content object, regardless of effectivity, which, in our case, is a bad thing. Even if the API was locked down, there’s no reason to make each front-end application duplicate the date handling logic. So the API handles that and other business rules around fetching content and constructing a response.
The native Elasticsearch API is Java, so building and executing queries in Java is a very natural thing to do. However, as the service evolved, the part of our code responsible for constructing the query was at risk of becoming unwieldy. We also started to identify new types of queries the front-end needed to execute that didn’t fit cleanly into our existing query-building logic.
In addition to identifying new types of queries the API needed to support, we began to see that the front-end applications would need to be able to provide more than just a flat list of key-value pairs–at the very least they would need to ask for content with parameters that included arrays and dictionaries as well.
The service had reached a point where it needed flexibility in the number and type of queries it could run and the parameters it could accept, but we didn’t want to expose the full power (and complexity) of the Elasticsearch Query DSL. Search templates to the rescue.
What is an Elasticsearch Search Template?
(This section contains embedded gists. If you can’t see them you may need to enable JavaScript. If all else fails, the gists live here.)
An Elasticsearch search template is kind of like a stored procedure in a relational database. Really, it’s just a normal query with replacement variables, aka template parameters. The templates are expressed using Mustache.
Here’s a simple example:
That example specified the template and the parameters in the same request. Obviously, if you’re going to do that you might as well not use a template.
What you’d rather do is put the template somewhere and then invoke it. You have two options. You can index the template or you can put the template on the file system.
Here’s how you index a template:
And then you can call it, like this:
If you’d rather put the template on the file system, it goes in $ES_HOME/config/scripts and is named template-id.mustache. Once you’ve deployed the template to every node in your cluster, you can call it, like this:
You don’t have to restart the node when you update a search template. Elasticsearch picks up the changes automatically. If you watch the log when you update a search template you should see something like:
Suppose we want to return all tweets unless a “since” parameter is provided. If since is specified, the query should do a date range against the timestamp property using the value provided. Mustache has some support for conditionals. Here’s how it looks in a search template:
This template will conditionally add the date range check only if the “since” parameter is provided.
Note: Be careful of spacing here. I like to put a space between my curly braces and the parameter. But if you do that in the conditional, mustache won’t recognize it.
To get the tweets for the last 30 days, you’d call the search template like this:
And to get all of the tweets you’d just omit the since parameter.
As your templates get more complex you might take a look at this tool. It allows you to quickly see how your templated queries will render given a set of parameters.
Using negation to implement if-then-else logic
Suppose that instead of returning all tweets we want to return just the last day of tweets unless the since parameter is specified. You’d like to use an if-then-else in the Mustache template. Else isn’t specifically supported by Mustache, but we can use negation to achieve the same thing.
This template keeps the clause that does the date check if since is specified, but now adds a default date check if it is not:
If the date is specified in the since parameter, it works as it did before. If not, only the last day of tweets will be returned.
Working with Arrays
Something that is kind of annoying is how to handle arrays. You can iterate over an array with Mustache fairly easily. But Mustache doesn’t have a mechanism for checking a position in an array such as “isLast” or “hasNext”, so if you need to do something like that, you’ll end up making your own construct.
For example, suppose we want to be able to pass in a list of user names to the search template to restrict the list of tweets to those specific users. The easy way to handle that in our query is to use a terms filter, like this:
But that doesn’t let me show how to work with arrays so I’m going to contrive the example to say that if a user list is provided, we need to add an “or” clause to the query with one term filter per user name.
To do that, we’ll require the list of users to be provided as a search template like this:
The template can check for the “userList” parameter to know whether or not to build the “or” clause. Then it can iterate over the “users” array, plucking out the name.
As the template iterates over the array, it needs to know whether or not it is on the last user. Otherwise it has no way of knowing whether or not to add the comma separating the term filters. Mustache can’t help us so the search parameter will include “isLast” set to true for the last user in the list.
Here’s a template that can handle the array of user names:
The result of calling the template above with the example user list is a query that looks like this:
With those simple constructs you ought to be able to create some very elaborate search templates.
Invoking search templates from the Java API
Back in the service layer, it is easy to invoke a search template with the Java API. Here’s how that looks:
In the real API, those params are getting POSTed to the endpoint.
Query changes without a code deployment
With search templates, we can add new queries and modify existing queries by creating and modifying search templates. This means for many adjustments, we don’t have to build and deploy the custom content service API code. And troubleshooting is easier too because we can invoke the same search template the service is using directly and not worry about whether or not the Java API is building the query we expect.
So the next time you find yourself writing code to construct an Elasticsearch query, ask yourself if it would make more sense to externalize it as a search template.
Almost all of my client work is remote. For many projects, that means chat is an essential communication tool. When you and your team essentially live in a chat window it’s nice when your tools can participate in the conversation. Luckily, it’s pretty easy to wire this up. Let me show you how I did it for a recent Elasticsearch project.
Openfire: An open source chat server
Today, hosted chat services like Slack and HipChat get all of the attention. The approach I outline in this blog post will work with those tools too, but on this particular project we’re running an open source chat server on-prem called Openfire. Openfire has been around for a long time. I like it because it is open source, easy to install, and will run anywhere you can run Java.
Because it implements an open protocol called XMPP (aka Jabber) there are a variety of chat clients that will work with it. Openfire ships a web-based client called Spark and some of my teammates use that, but most of the time I use Adium on my Mac.
If you need help installing Openfire, take a look at the docs.
Inbound and outbound integration with Elasticsearch
Once your chat solution is working, it’s time to integrate it with Elasticsearch. For my requirements I needed two “directions” for this integration. First, I wanted to be able interrogate one or more of my Elasticsearch clusters from within chat. This “outbound” integration requires a “bot”. There are many open source bots to choose from and examples of bot scripts working with Elasticsearch. I’ll cover both shortly.
The other direction I needed was “inbound”–I wanted my Elasticsearch cluster to be able to tell the chat server when something is wrong with the cluster. This requires something to monitor the health of the cluster (we use Watcher, a paid add-on from Elastic) and a web hook that can use the chat server API to send messages.
Let me cover the outbound implementation–the bot–first. Then I’ll talk about Watcher and the web hook which make up the inbound implementation.
Hubot: An open source chat bot from Github
There are a number of chat bots out there. I went with Hubot from Github. Hubot is based on Node.js. Hubot scripts are written in Coffeescript. However, if you are new to Node or Coffeescript there are plenty of examples out there so don’t let that stop you from using Hubot.
I used this blog post to get Hubot working. However, there were a few gotchas I should point out:
I had to use an old version of node.js (0.10.23). The newer version was having a lot of trouble with one of its dependencies and I got tired of fooling with it.
The blog post lists some Linux dependencies you need to install, but it leaves one out that’s critical: libicu. On Centos this is libicu-devel and on Ubuntu it is libicu-dev.
The blog post specifies some environment variables that need to be set. If you are running Hubot with Openfire, the HUBOT_XMPP_ROOMS variable needs to be set to the fully-qualified conference room name. For example, if the Hubot username is “hubot” running on a host named “grumpy” the variable should be set to hubot@conference.grumpy.
You may have to set HUBOT_XMPP_HOST to the hostname of your Openfire server.
Other than that, you should be able to use that blog post to get Hubot and Openfire working.
Hubot and Elasticsearch
There are Hubot scripts that do all sorts of stuff. One of the fun things about adding a bot to your chatroom is to have it do something silly. Maybe every time someone uses the word “Dude” the bot throws out a quote from the Big Lebowski, for example. So you’ll see lots of stuff like that. But there are also more useful examples out there. Here is the one I started with. The hubot-elasticsearch script knows how to use the Elasticsearch API to spit out information about nodes, indices, allocation, and settings. And it allows you to alias your clusters so you don’t have to constantly tell the bot what your URL endpoints are.
Out-of-the-box, the hubot-elasticsearch project is not compatible with Shield, but it’s a decent start. I made a small tweak to get it to work with Watcher, which I’ll cover next.
Watcher: Monitoring and Alerting for Elasticsearch
This particular client is a paying customer of Elastic, which means they are entitled to paid-only add-ons such as Shield (secures the cluster) and Watcher (for monitoring and alerting).
Watcher is pretty handy and we’re glad to have it, but if you aren’t able to use it for some reason, writing your own tool for running tasks on a schedule isn’t too tough. I wrote something similar using Spring MVC and Quartz, for example. You just need something that will periodically interrogate the cluster and then take some action based on some condition. But if you are an Elastic customer there’s no need to build it. The rest of the post assumes that’s the case.
I’ll let you read the Watcher docs to learn more, but at a high level, a watch consists of a trigger, an input, a condition, and an action. The trigger is the schedule. The input might be an Elasticsearch query or the response from some random HTTP endpoint. The condition looks at the input and then decides whether or not action is needed. The action taken might be to send an email, create some data in Elasticsearch, or invoke a web hook.
For my needs, the web hook action is perfect–if one of my watch conditions is met, like maybe something goes wrong with my cluster and the cluster state goes to red, Watcher will invoke my web hook which will post a message in the chat room. Here’s what the action part of my watch definition looks like:
"actions": {
"notify_chat": {
"webhook": {
"method": "POST",
"host": "localhost",
"port": 8008,
"path": "/chat",
"headers": {
"Content-Type": "application/json"
},
"body": "cluster_health alert: Someone needs to look at the DEV cluster. It appears to be in a RED state."
}
}
}
Watcher can have any number of actions listed for a given watch. In this case, I’m using a single “webhook” action called “notify_chat” that does a POST to a URL running on port 8008. That URL could be anything, and it can include basic authentication.
Web Hook: Spring Boot, Spring MVC, and Smack
I’ve been using Spring Boot lately when I need to knock out a quick RESTful API. In this case, I just needed something to listen to the “/chat” end point. When it is called, the code grabs the message posted to it and uses the Smack API to connect to the chat room and post the message. This webapp is probably less than 10 lines of code and Spring Boot packages it up nicely for me.
Watcher can throttle or suppress actions based on a time period (“Don’t tell me about this condition again for 5 minutes,” for example) or explicit acknowledgement. If a watch is triggered that uses explicit acknowledgement, I want to be able to acknowledge that from within chat. You already saw that the Elasticsearch Hubot script can talk to the cluster. It’s pretty easy to tweak the script to allow Watcher acknowledgement.
First, I added a function called “ackWatch” that actually does the work of acknowledging the watch:
Then, I added the regular expression that the bot should be listening for:
robot.hear /elasticsearch ack (.*) (.*)/i, (msg) ->
if msg.message.user.id is robot.name
return
ackWatch msg, msg.match[1], msg.match[2], (text) ->
msg.send text
With that in place, any user in the chat room can acknowledge a watch by typing, “hubot: elasticsearch ack some_watch some_alias” where some_watch is the ID of a watch and some_alias is the nickname for the cluster you’re talking about (like “dev”, “qa”, or “prod”, for example).
Putting it all together: A short demo
With all of this in place, my Elasticsearch clusters can tell the team when something interesting is going on and the team can acknowledge that alert and do preliminary investigation by interrogating the cluster, all from the comfort of their chat window.
The video below shows this working. In it, I create a simple watch that invokes a web hook to post a message to the chat room when a watch condition is met.
The demo uses a simple example where the alert is triggered when the test index is a certain size. But you could easily wire up any watch to the same action, such as when your cluster state goes red or when CPU or RAM reach a certain threshold.
This was relatively simple to put together, but hopefully you can see how you could build on this to automate all kinds of things related to monitoring, alerting, and administration of your Elasticsearch cluster from chat.
I am seeing a lot of interest in Elasticsearch from clients and colleagues. Elasticsearch is an open source search engine that is commercially supported by a company called Elastic. It’s used for web search, log analysis, and big data analytics. You’ll often see it compared with Apache Solr. Both depend on Apache Lucene for low-level indexing and analysis. People like Elasticsearch because it is easy to install, scales out to hundreds of nodes with no additional software needed, and is easy to work with thanks to its built-in RESTful API.
Multiple folks have asked me what they need to think about when leveraging Elasticsearch as part of their solution, so I thought I’d summarize those thoughts and share them here. This isn’t a detailed technical list but is more like a set of buckets that need time and attention.
1.Cluster sizing
The nice thing about Elasticsearch is how easy it is to scale out. But you should still have an idea of the near- and medium term hardware footprint. Indexing and querying time can vary depending on many factors and every installation is different. You’ll want to establish your “unit of scale” early so you know roughly what you’ll have to do to get a target level of throughput and CPU utilization.
Related to cluster sizing is your cluster footprint. Elasticsearch nodes can be master nodes, data nodes, client nodes, or some combination. Most people opt for dedicated master nodes (3 at a minimum) and then some number of data and client nodes.
I like using dedicated nodes for everything because it separates responsibilities and lets you optimize each type of node for its particular workload. For example, I’ve seen a performance boost by separating client and data nodes. The client nodes handle the incoming HTTP requests which leaves the data nodes to service the queries.
Like sizing, the footprint that works well for you depends on what you’re doing, so use something like JMeter to test repeatedly until you get it right.
3.Security
You’ll need to secure your Elasticsearch cluster, both between the application/API and Elasticsearch layers and between the Elasticsearch layer and your internal network. Shield, which is a paid product from Elastic, can take you a lot of the way here and if you pay for support from Elastic, Shield is included.
One of my projects uses Shield to provide LDAP authentication, to encrypt all data between Elasticsearch nodes with SSL, and to control authorization for all of the indices in the cluster. We’ve been happy with it so far.
If you can’t justify a support subscription you’ll need to do something else to prevent unauthorized access to your cluster. Using something like nginx as a proxy is a common choice.
4.Index/Alias/Type Mapping approach
You might call this your data partitioning and data modeling approach. You should figure out early what your approach to indices and aliases will be. You’ll definitely want to use aliases–that’s a given. Aliases insulate your app from index name changes among other things. But some thought also needs to be given to how you partition data across indices.
You’ll also need to identify how you’ll leverage type mappings. Elasticsearch is schema-less but type mappings of some kind are almost always needed so that Elasticsearch knows how to index the data (longs versus dates versus strings, for example).
I’m building a dynamic content service on top of Elasticsearch for one of my clients. They have many different types of content that will be indexed in Elasticsearch and returned to their e-commerce app as JSON chunks. A lot of time is going into defining the JSON structure for those types which ultimately gets translated into type mappings.
The Elasticsearch query DSL is vast. At a high level you will deal with queries and filters depending on exactly what you need to do. You’ll want to avoid queries, if possible, and lean toward filters. They are much, much more performant.
More than just query design, you’ll want to figure out how you’re going to expose queries to the API. On a recent project we started by having our Java-based API layer translate developer-friendly query string params into Elasticsearch filters. We didn’t stick with that, though, because tuning and tweaking our queries required the API layer to be re-compiled and deployed. We now do everything with search templates which pulls our query logic out of the Java code and makes it easier to manage.
Understanding how to write efficient queries is one thing, but making them return the results that end-users expect is another. Once written, expect to spend some time tweaking analyzers and scoring so that the engine returns the right hits. If this is a particular concern for you take a look at the Relevant Search book from Manning.
6.Monitoring & Alerting
Be sure to factor in a completely separate “monitoring” cluster that will only be used to capture stats about the health of the cluster and alert you when something goes wrong. Two tools that work great for this are Marvel and Watcher.
Marvel keeps track of the health of the cluster and Sense (built-in to Marvel) is used to run ad hoc operations against the cluster. Marvel includes a dashboard that reports on the health of the cluster.
Elastic just released a new tool called Watcher. It watches for certain conditions and alerts you when those conditions are met. So when some stat (JVM heap, for example) reaches a threshold you can take some action (send an email, call a web hook, etc.).
Watcher isn’t just for monitoring the health of the cluster. Watcher can monitor searches against any index. In fact, Watcher can invoke any HTTP end point and then take action based on what comes back.
7.Node provisioning and config management
Once you have more than a handful of nodes it becomes challenging to keep every node in sync with regard to software versions, configuration, etc. There are a number of open source tools that can help with this. I’ve used both Chef and Ansible to help manage Elasticsearch clusters. By far, my favorite tool for this is Ansible. It automates upgrades and configuration propagation without requiring any additional software to be installed on any of the Elasticsearch nodes.
You may not see a huge need for automation now, but if you’re going to start small and grow, you’ll want to be able to grow quickly. Having a library of common tasks scripted with Ansible will allow you to go from bare server to fully-provisioned Elasticsearch node in minutes with no manual intervention.
In addition to automating installs and config changes, you’ll have a need for scheduling routine administrative tasks like copying an index or cleaning up old indices that Marvel and Watcher create daily. I use a “job server” that I built from open source components to do this. Cron jobs are also a common approach.
8. Backup and recovery
Properly tuned, indexing can run pretty fast even for very large data sets. So some people opt to simply re-index if they lose data. Elasticsearch has built-in “snapshot” functionality that can back up your indices. If you do something to handle scheduled operations (see “job server”, above) then taking regular snapshots easy to do. Relying on OS-level file system backups may be dicey once you have multiple nodes due to how the data is stored.
9. API & UI development
It is likely that you’ll put Elasticsearch behind an API layer that provides an agnostic API to applications that are leveraging your search cluster. You may also want to do some transformation of input or output before and after requests hit Elasticsearch. Exactly what you use for this is up to you–there are Elasticsearch clients for most popular languages and you can always just use the REST endpoints if needed. I’ve implemented this layer using Node.js, Java, and Lua and they each have pluses and minuses, as usual.
Everything you index into Elasticsearch is JSON. So any tool that can speak HTTP and post JSON can be used to work with the server. Elastic offers a tool called Marvel that embeds another tool called Sense (also available as a Chrome extension) that is extremely useful for doing this. Of course command-line tools like curl also work well.
Depending on the makeup of your team and the use case, you may find that writing a custom UI to manage the documents indexed into Elasticsearch, rather than using Sense or curl, is the way to go. This is just a web development task, thanks to the Elasticsearch REST API, but obviously it takes time that needs to be accounted for in your plans.
10. Data indexing
It is easy to index data into Elasticsearch. Depending on the data source and other factors, you might write this yourself or you can use another tool from Elastic called Logstash. Logstash can watch log files or other inputs and then efficiently index the data into your cluster.
Summary
Installing and running an out-of-the-box Elasticsearch cluster is easy. Making it work for your exact use case and keeping everything humming along takes a bit more effort. Hopefully this list has given you a rough idea of the areas where you’ll likely need to spend time as you move forward with your Elasticsearch project.
In my last blog post I showed how to use Apache JMeter to run a load test against Elasticsearch or anything with a REST API. One of my recommendations was to turn off all of the Listeners so that valuable test client resources are not wasted on aggregating test results. So what’s the best way to analyze your load test results?
Our load test was running against Elasticsearch which just happens to have a pretty nice tool set for ingesting, analyzing, and reporting on any kind of data you might find in a log file. It’s called ELK and it stands for Elasticsearch, Logstash, and Kibana. Elasticsearch is a distributed, scalable search engine and document oriented NoSQL store. Logstash is a log parser that can send log data to various outputs. Kibana is a tool for defining dashboards that contain charts, graphs, and tables based on data stored in Elasticsearch.
It is really quite easy to use ELK to create a dashboard that aggregates and displays Apache JMeter test results in realtime. Here’s how.
Step One: Configure Apache JMeter to Create a CSV File
Another recommendation in my last post was to use the Apache JMeter GUI only for testing and to run your load test from the command line. For example, this runs my test named “Basic Elasticsearch Test.jmx” from the command line and writes the results to results.csv:
The results.csv file will get fed to Logstash and ultimately Elasticsearch so it can be reported on by Kibana. The Apache JMeter user.properties file is used to specify what gets written to results.csv. Here is a snippet from mine:
Pay attention to that timestamp format. You want your Apache JMeter timestamp to match the default date format in Elasticsearch.
Step Two: Configure and Run Logstash
Next, download and unpack Logstash. It will run on the same machine as your test client box (or on a box with file access to the results.csv file that JMeter is going to create). It also needs to be able to get to Elasticsearch over HTTP.
There are two steps to configuring Logstash. First, Logstash needs to know about the results.csv file and where to send the log data. The second part is that Elasticsearch needs a type mapping so it understands the data types of the incoming JSON that Logstash will be sending to it. Let’s look at the Logstash config first.
The Logstash configuration is kind of funky, but there’s not much to it. Here’s mine:
The “input” part tells Logstash where to find the JMeter results file.
The “if” statement in the “filter” part looks for the header row in the CSV file and discards it if it finds it, otherwise, it tells Logstash what columns are in the CSV.
The “output” part tells Logstash what to do with the data. In this case we’ll use the elasticsearch_http plugin to send the data to Elasticsearch. There is also one that uses the native API but when you use that, you have to use a specific version combination of Logstash and Elasticsearch.
A quick side note: In our case, we were running a load test against an Elasticsearch cluster. We use Marvel to report on the health of that cluster. To avoid affecting production performance, Marvel sends its data to a separate monitoring cluster. Similarly, we don’t want to send a bunch of test result data to the production cluster that is being tested, so we configured Logstash to send its data to the monitoring cluster as well.
That’s all the config that’s needed for this particular exercise.
Here are a couple of Logstash tips. First, if you need to see what’s going on you can add a sysout to the configuration by adding this line between ‘output {‘ and ‘elasticsearch_http {‘ before starting logstash:
stdout { codec => rubydebug }
The second tip is about re-running Logstash and forcing it to re-parse a log file it has already read. Logstash remembers where it is in the log. It does this by writing a “sincedb” file. So if you need to re-parse the results.csv file, clear out your sincedb files (mine live in ~/.sincedb*). You may also have to add “start_position => beginning” to your Logstash config on the line immediately following the path statement.
Okay, Logstash is ready to read the Apache JMeter CSV and send it to Elasticsearch. Now Elasticsearch needs to have an index and a type mapping ready to hold the log data. If you’ve spent any time at all with Elasticsearch you should be familiar with creating a type mapping. In this case, what you want to do is create a type mapping template. That way, Logstash can create an index based on the current date, and it will use the correct type mapping each time.
Now Logstash is configured to read the data and Elasticsearch is ready to persist it. You can test this at this point and verify that the data is going all the way to Elasticsearch. Start up Logstash like this:
If it looks happy, go start your load test. Then use Sense (part of Marvel) or a similar tool to inspect your Elasticsearch index.
Step 3: Visualize the Results
Now it is time to visualize all of those test results coming from the load test. To do that, go download and unpack Kibana. I followed a tip in this blog post and unpacked it into $ES_HOME/plugins/kibana/_site on my monitoring cluster but you could use some other HTTP server if you’d rather.
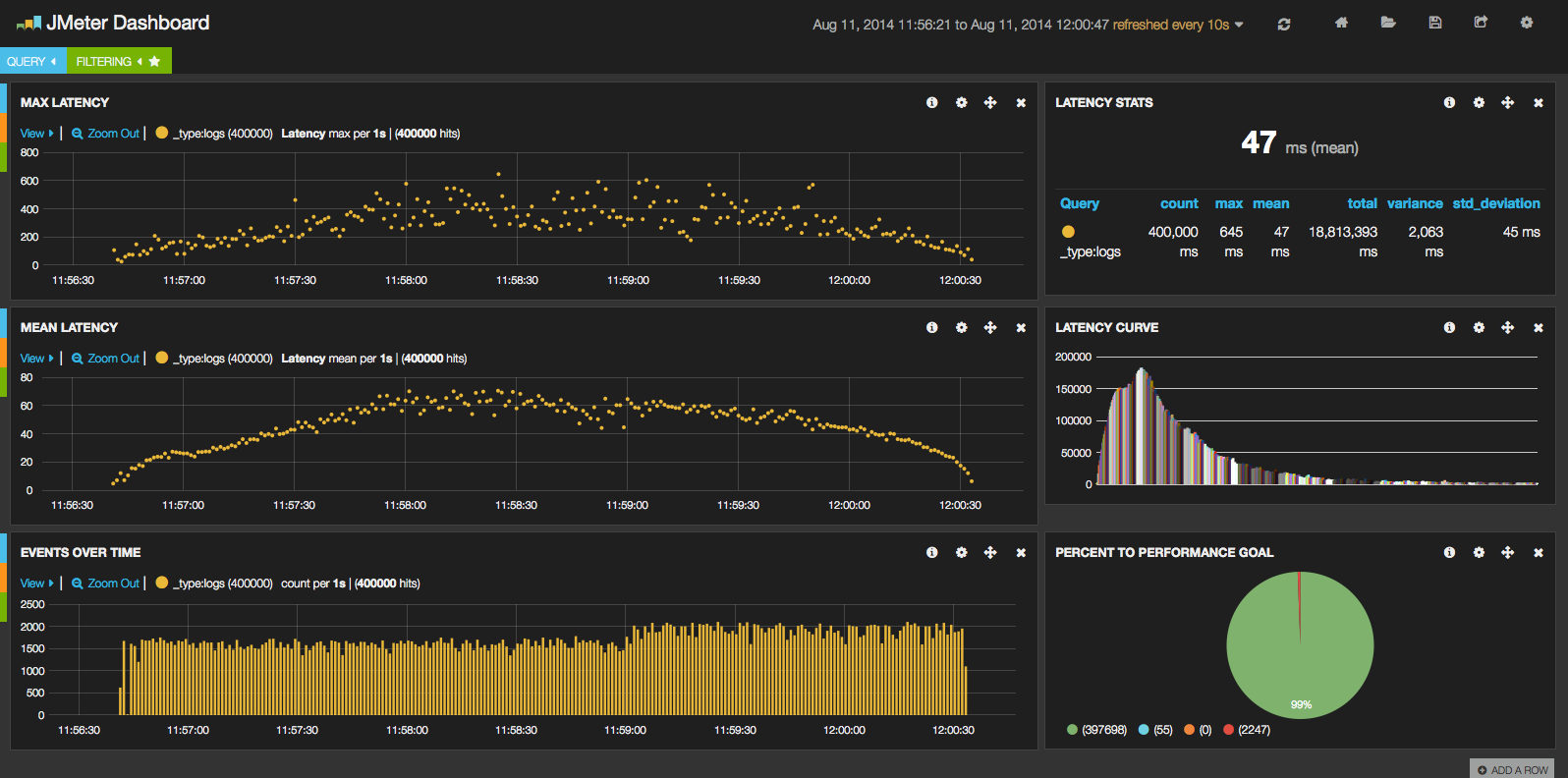
Now open a browser and go to Kibana. You can link to a Logstash dashboard, a sample dashboard, an unconfigured dashboard, or a blank dashboard. Pick one and start playing with it. Once you get the hang of it, create your JMeter Dashboard starting from a blank dashboard. Here’s what our dashboard looked like when it was done:
Click to see the screenshot in all of its glory.
Using Logstash and Kibana we can see, in realtime, the throughput our Apache JMeter test is driving (bottom left) and a few different panels breaking down response latency. You can add whatever makes sense to you and your team. For example, we want all of our responses to come back within 250 ms, so the chart on the bottom right-hand corner shows how we’re doing against that goal for this test run.
One gotcha to be aware of. By default, Kibana looks at the Elasticsearch timestamp. But that’s the time that Logstash indexed the content, not the actual time that the HTTP request came back to Apache JMeter. That time gap could be small if you are running Logstash while your test is running and your machine has sufficient resources, or it could be very large if you wait to parse your test results for some time after the test run. Luckily, the timestamp field that Kibana uses is configurable so make sure all of your graphs are charting the appropriate timestamp field, which is the “time” field that JMeter writes to the CSV file.
I’m helping a client streamline their Web Content Management processes, part of which includes moving from a static publishing model to a dynamic content-as-a-service model. I’ll blog more on that some other time. What I want to talk about today is how we used Apache JMeter to validate that Elasticsearch, which is a core piece of infrastructure in the solution, could handle the load.
Step 1. Find some test data to index with Elasticsearch
Despite being a well-known commerce site that most of my U.S. readers would be familiar with, my client’s site’s content requirements are relatively modest. On go-live, the content service might have 10 or 20 thousand content objects at most. But we wanted to test using a data set that was much larger than that.
We set out to find a real world data set with at least 1 million records, preferably already in JSON, as that’s what Elasticsearch understands natively. Amazon Web Services has a catalog of public data sets. The Enron Email data set looked most promising.
We ended up going with a news database with well over a million articles because the client already had an app that would convert the news articles into JSON and index them in Elasticsearch. By using the Elasticsearch Java API and batching the index operations using its bulk API we were able to index 1.2 million news articles in a matter of minutes.
Step 2: Choosing the Testing Tool & Approach
We looked at a variety of tools for running a load test against a REST API including things like siege, nodeload, Apache ab, and custom scripts. We settled on Apache JMeter because it seemed like the most full-featured option, plus I already had some familiarity with the tool.
For this particular exercise, we wanted to see how hard we could push Elasticsearch while keeping response time within an acceptable window. Once we established our maximum load with a minimal Elasticsearch cluster, we would then prove that we could scale out roughly linearly.
Step 3: Defining the Test in Apache JMeter
JMeter tests are defined in JMX files. The easiest way to create a JMX file is to use the JMeter GUI. Here’s how I defined the basic load test JMX file…
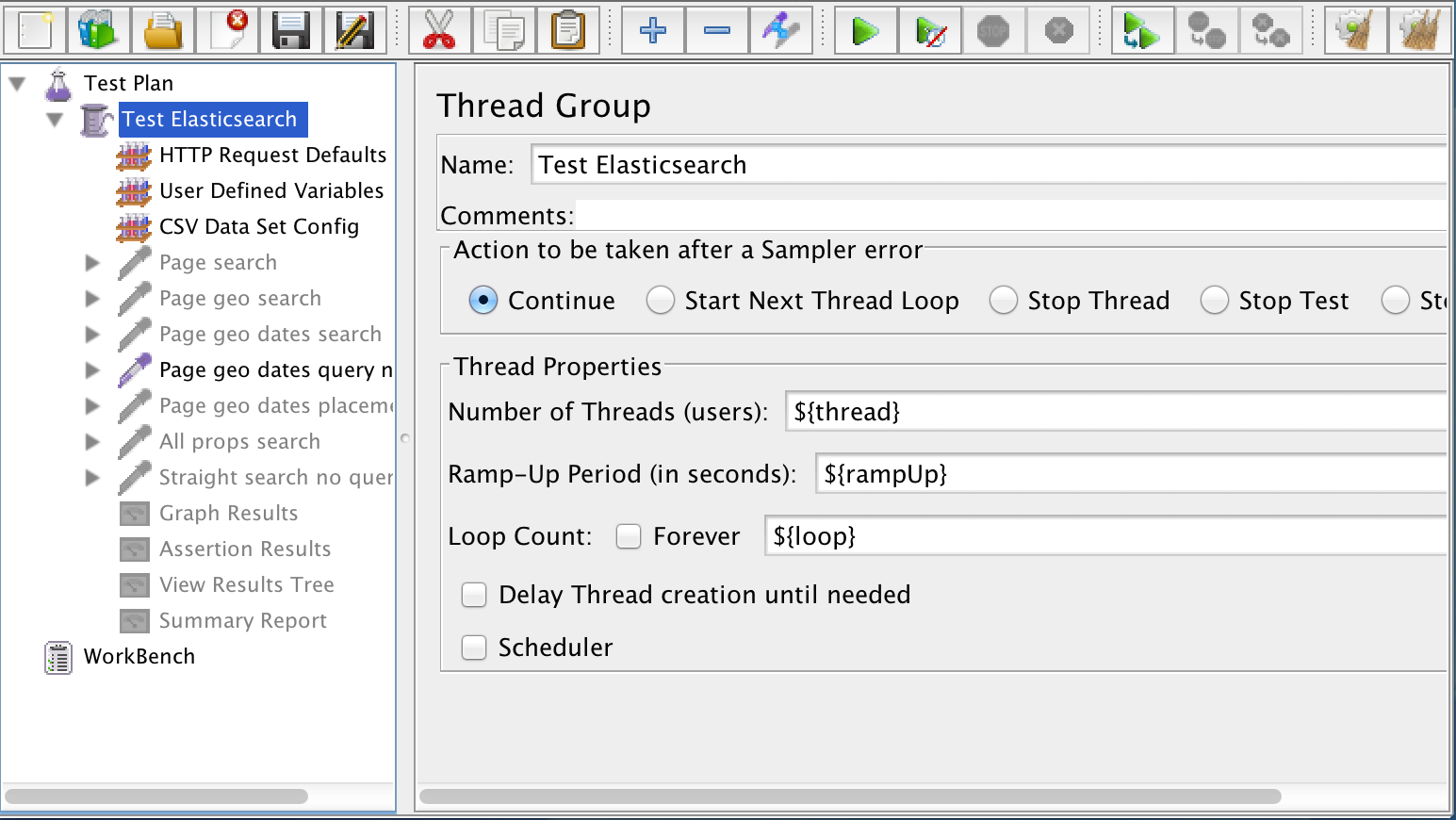
First, I created a thread group. Think of this like a group of test users. The thread group defines how many simultaneous users will be running the test, how fast the ramp-up will be, and how many loops through the test each user will make. You can see by the screenshot below that I used parameters for each of these to make it easier to change the settings through configuration.
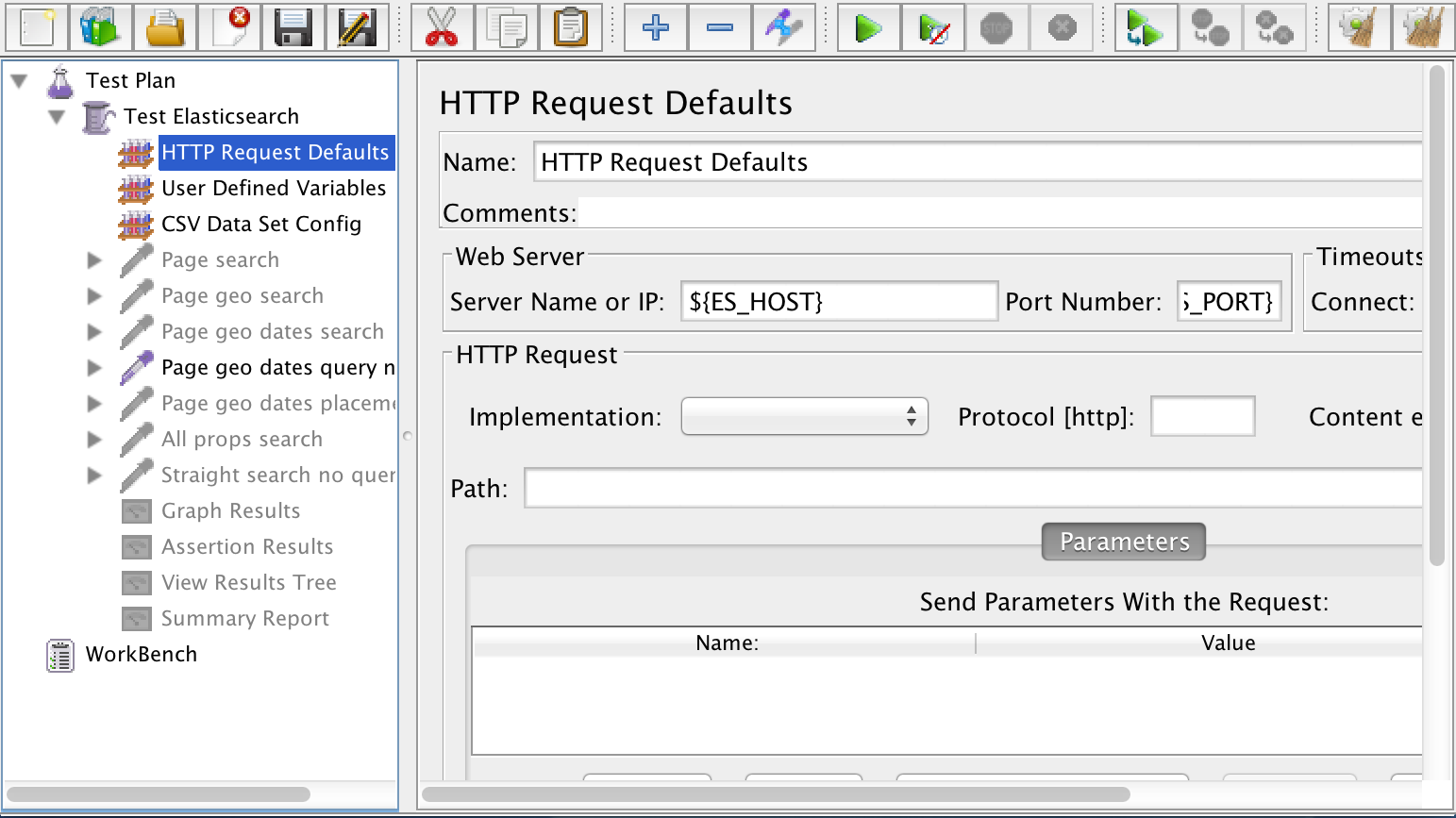
Within the thread group I added some HTTP Request Defaults. This defines my Elasticsearch host and port once so I don’t have to repeat myself across every HTTP request that’s part of the test.
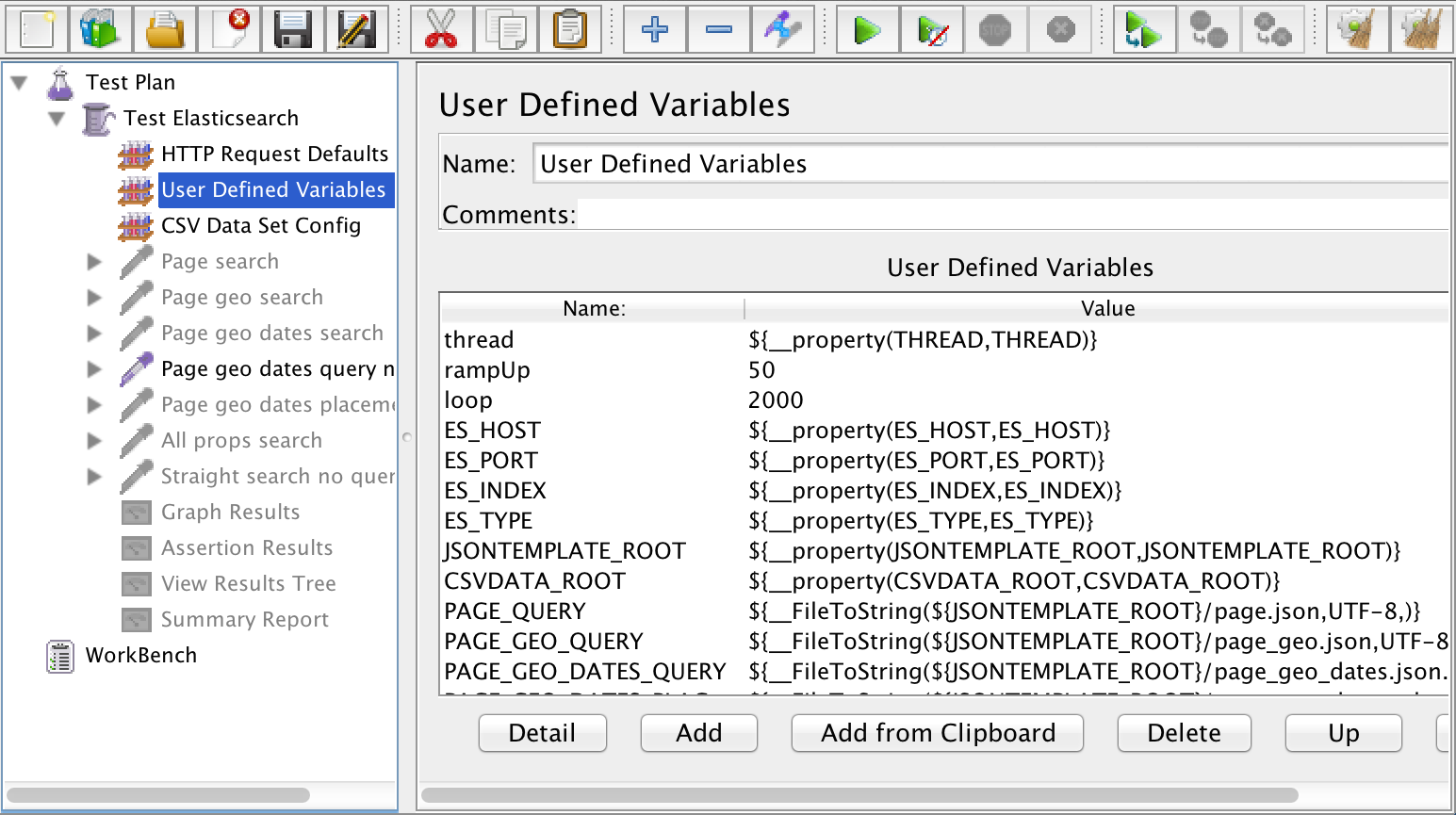
Next are my User Defined Variables. These define values for the variables in my test. Look at the screenshot below:
You’ll notice that there are three different kinds of variables in this list:
Hard-coded values, like 50 for rampUp and 2000 for loop. These likely won’t change across test runs.
Properties, like thread, ES_HOST, and ES_PORT. These point to properties in my JMeter user.properties file.
FileToString values, like for PAGE_GEO_QUERY. These point to Elasticsearch query templates that live in JSON files on the file system. JMeter is going to read in those templates and use them for the body of HTTP requests. More on the query templates in a minute.
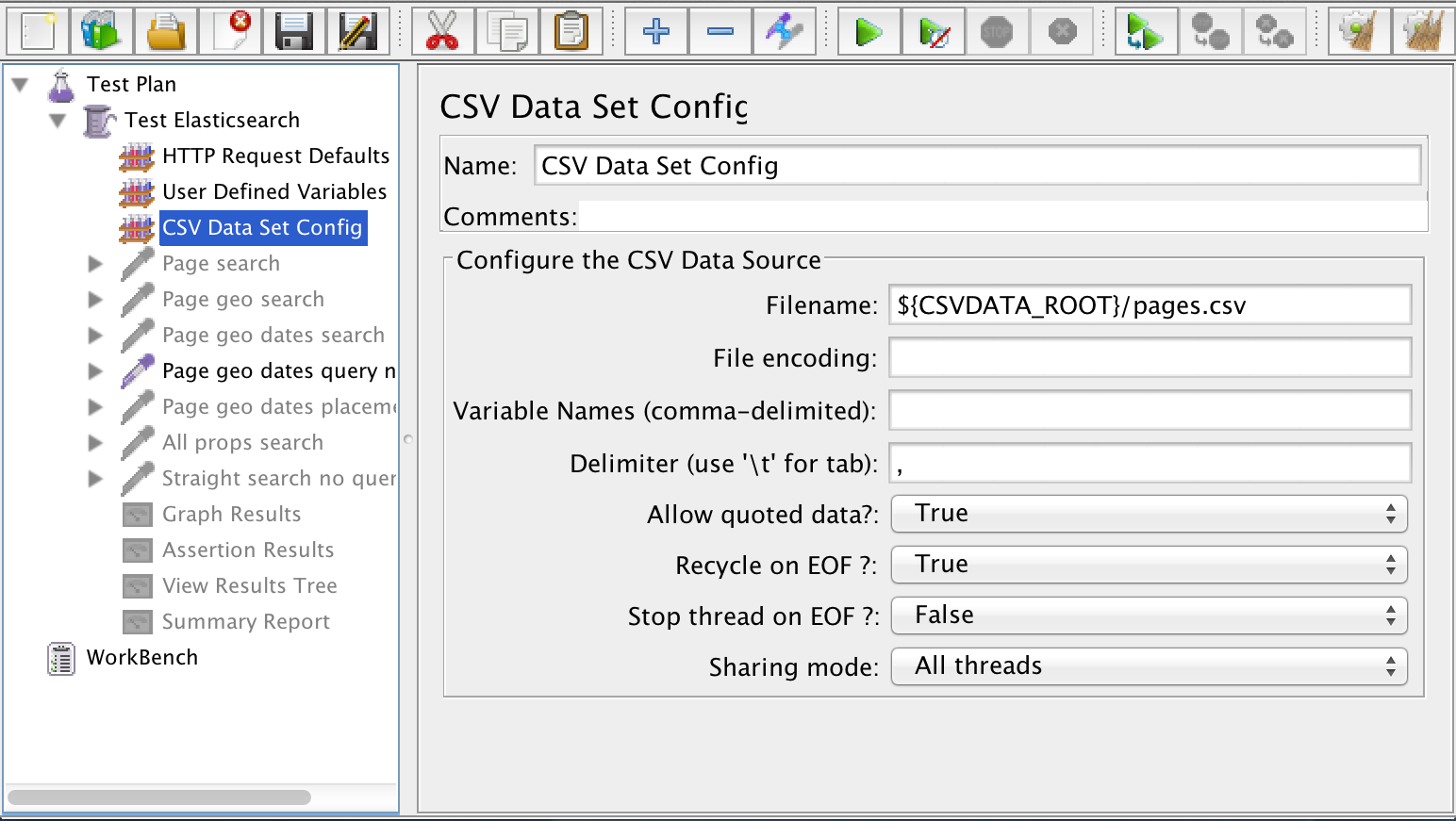
The third configuration item in my test definition is a CSV Data Set Config. I didn’t want my Elasticsearch queries to use the same values on every HTTP request. Instead I wanted that data to be randomized. Rather than asking JMeter to randomize the data, I created a CSV file with randomized data. Reading data from a CSV to use for the test run is less work for JMeter to do and gives me a repeatable, but random, set of data for my tests.
You can see that the filename is prefaced with “${CSVDATA_ROOT}”, which is a property declared in the User Defined Variables. The value of it resides in my JMeter user.properties file and tells JMeter where to find the CSV data set.
Here is a snippet of my user.properties file: ES_HOST=127.0.0.1
ES_PORT=9200
ES_INDEX=content-service-content
ES_TYPE=wcmasset
THREAD=200
JSONTEMPLATE_ROOT=/Users/jpotts/Documents/metaversant/clients/swa/code/es-test/tests/jsontemplates
CSVDATA_ROOT=/Users/jpotts/Documents/metaversant/clients/swa/code/es-test/tests/data
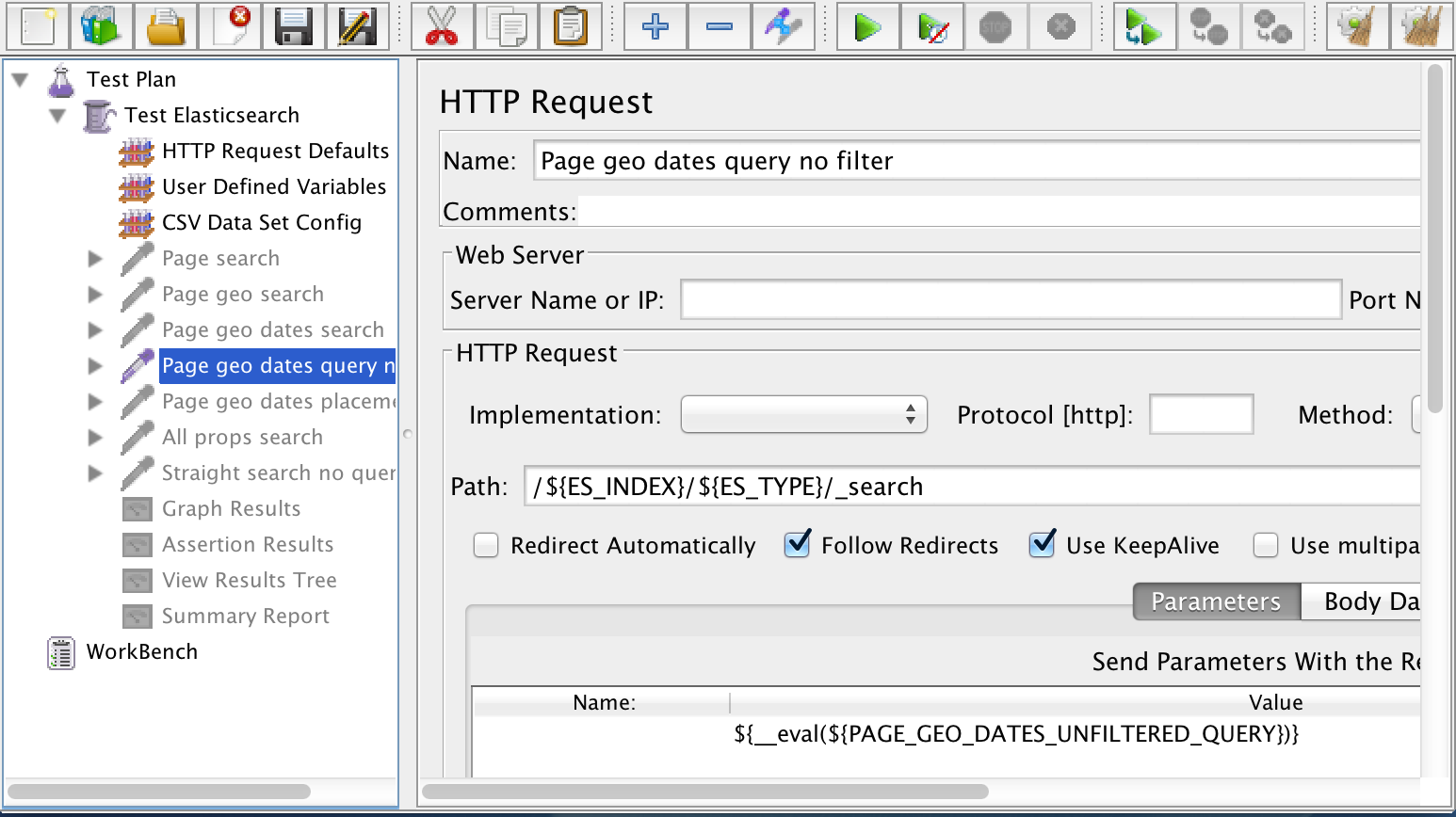
Next comes the actual HTTP requests that will be run against Elasticsearch. I added one HTTP Request Sampler for each Elasticsearch query. I have multiple HTTP Request Samplers defined–I typically leave all but one disabled for the load test depending on the kind of load I’m trying to test.
You can see that I didn’t have to specify the server or port because the HTTP Request Defaults configuration took care of that for me. I specified the path, which is the Elasticsearch URL, and the body of the request, which resides in a variable. In this example, the variable is called PAGE_GEO_DATES_UNFILTERED_QUERY. That variable is defined in User Defined Variables and it points to a FileToString value that resolves to a JSON file containing the Elasticsearch query.
Okay, so what are these query templates? You’ve probably used curl or Sense (part of Marvel) to run Elasticsearch queries. A query template is that same JSON with replacement variables instead of actual values to search for. JMeter will merge the test data from the randomized test data CSV with the replacement variables in the query template, and use the result as the body of the HTTP request.
Here’s an example of a query template that runs a filtered query with four replacement variables used as filter values:
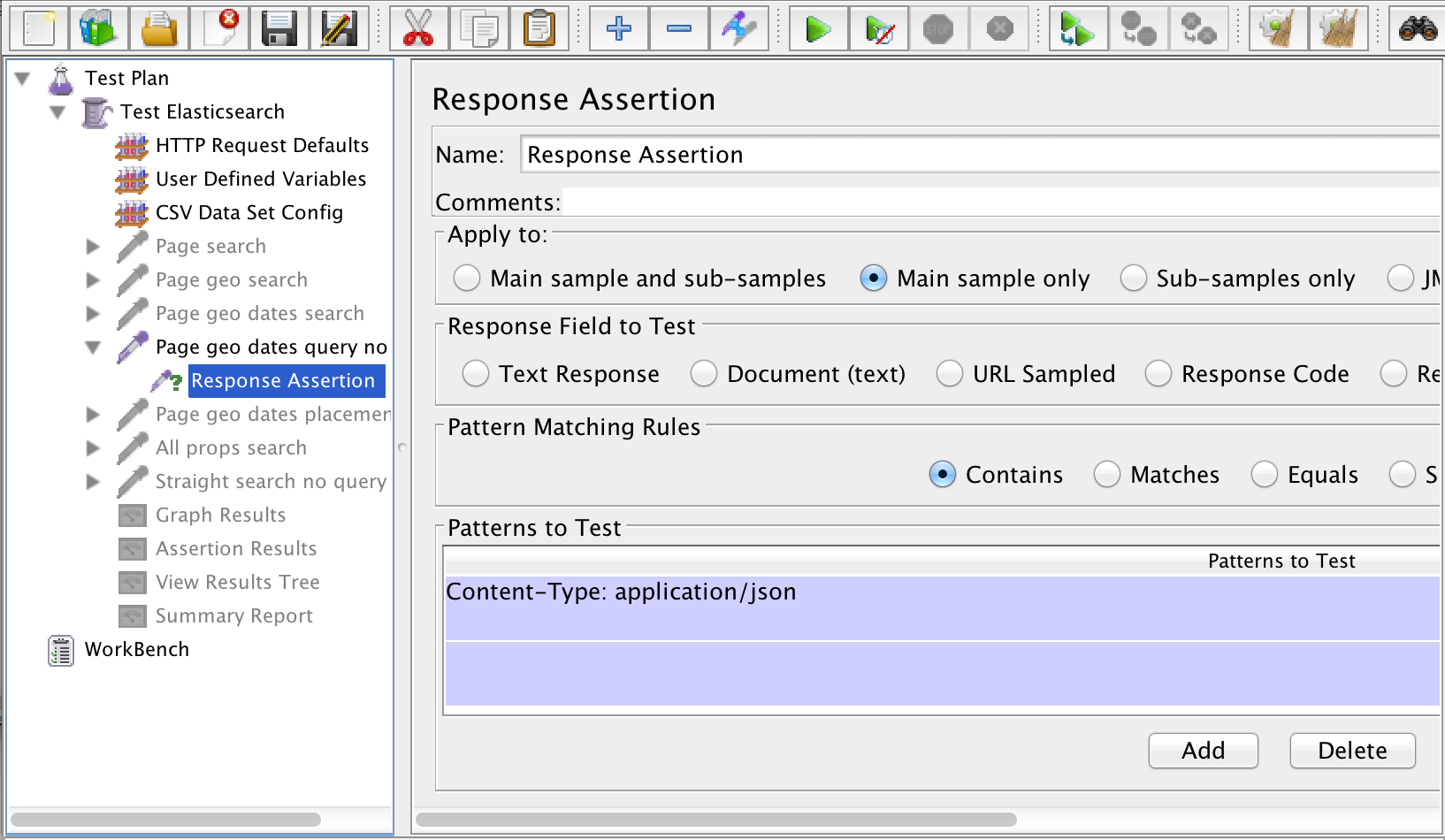
JMeter lets you inspect the response that comes back from the HTTP Request using assertions. However, the more assertions you have, the more work JMeter has to do, so it is recommended that you have as few as possible when doing a load test. In my test, I added a single assertion for each HTTP Request that looks only at the response header to make sure that I am getting back JSON from the server. JMeter provides a number of Listeners that summarize the responses coming back from the test. You may find things like the Assertion Results, View Results Tree, and Summary Report very helpful while you are writing and testing your JMX file in the JMeter GUI, but you will want to make sure that all of your Listeners are completely disabled when running your load test for real.
At the end of this step I’ve got a repeatable test that will run 400,000 queries against Elasticsearch (that’s 200 threads x 2,000 loops x 1 enabled HTTP request). Because everything is configurable I can easily make changes as needed. The next step is running the test.
Step 4: Run the test
The first thing you have to deal with before running the test is driving enough traffic to tax your server without over-driving the machine running JMeter or saturating the network. This takes some experimentation. Here are some tips:
Don’t run your test using the JMeter GUI. Use the command line instead.
Don’t run Elasticsearch on the same machine that runs your JMeter test.
As mentioned earlier, use a very simple assertion that does as little as possible, such as checking the response header.
Turn off all Listeners. I’ll give you an approach for gathering and visualizing your test results that will blow those away anyway.
Don’t exceed the maximum recommended number of threads (users) per test machine, which is 300.
Use multiple JMeter client machines to drive a higher concurrent load, if needed.
Make sure your Elasticsearch query is sufficient enough to tax the server.
This last point was a gotcha for us. We simply couldn’t run enough parallel JMeter clients to stress the Elasticsearch cluster. The CPU and RAM on the nodes in the Elasticsearch cluster were barely taxed, but the JMeter client machines were max’d out. Increasing the number of threads didn’t help–that just caused the response times JMeter reported to get longer and longer due to the shortage of resources on the client machines.
The problem was that many of our Elasticsearch queries were returning empty result sets. We had indexed 1.2 million news articles with metadata ranges that were too broad. When we randomized our test data and used that test data to create filter queries, the filters were too narrow, resulting in empty result sets. This was neither realistic nor difficult for the Elasticsearch server to process.
Once we fixed that, we were able to drive our desired load with a single test client and we were able to prove to ourselves that for a given load driven by a single JMeter test client we could handle that load with an acceptable response time using an Elasticsearch cluster consisting of a single load-balancing node and two master/data nodes (two replicas in total). We scaled that linearly by adding another 3 nodes to the cluster (one load-balancer and two master/data nodes) and driving it with an additional JMeter client machine.
Visualizing the Results
When you do this kind of testing it doesn’t take long before you want to visualize the test results. Luckily Elasticsearch has a pretty good offering for doing that called ELK (Elasticsearch, Logstash, & Kibana). In my next post I’ll describe how we used ELK to produce a real-time JMeter test results dashboard.