I’ve known Michael Uzquiano, Cloud CMS CTO, and Malcolm Teasdale, Cloud CMS CEO, for at least a decade, so it’s been fun to watch as Cloud CMS has matured over the years.
As a Cloud CMS partner, I often talk to them about issues or ideas related to projects I’m doing for clients with Cloud CMS. Over the years we’ve occassionally found time to chat about more strategic topics. Both the tactical and strategic conversations have been valuable for both sides, but they were definitely ad hoc.
Recently, Malcolm asked if I’d be up for making those conversations more regular and potentially a bit deeper by making me part of the advisory team. Liking both the people and the tech, this sounded like a great idea to me.
Nothing changes for my clients or my company, Metaversant Group, other than the additional insight I might gain from discussions with the Cloud CMS team.
As far as this blog goes, I’ll continue to write about Cloud CMS and others in this space as I’ve done in the past, on topics that interest me. My friends at Cloud CMS might help inform me on technical details for Cloud CMS-related posts, but they won’t be making any editorial decisions. I know my readers value my transparency and openness and that will continue.
I think de-coupled content management is just starting to hit its stride and I’ve enjoyed working with Cloud CMS thus far. I’m definitely looking forward to continuing the discussions with the Cloud CMS crew about company and product direction.
Alfresco DevCon is coming up, so I’ve been wondering about what kind of new and innovative things Alfresco might be sharing with us at the conference. That got me thinking about whether or not Alfresco is still innovating and if those innovations need to appeal to developers or business users for Alfresco to stay relevant. My opinion on that might surprise you. Let me explain.
Back in 2010 I wrote a blog post called “Alfresco, NoSQL, and the future of ECM“. In that post I pointed out that NoSQL offered many features attractive to developers of content-centric solutions such as the lack of a schema, ease of replication, and their ability to scale. I predicted that new content management and document management vendors would enter the market with native NoSQL solutions, existing vendors would start to take advantage of NoSQL, and customers would develop their own content-centric solutions built on NoSQL instead of relational repositories.
It didn’t take long for all of these predictions to come true (not that they were much of a stretch!). New content management players like Contentful and CloudCMS arrived (See “The Emerging Content-as-a-service market“, 2014), both of which rely heavily on NoSQL stores.
Nuxeo, who Gartner named a visionary in the ECM space, now offers MongoDB instead of or along-side a relational database. Nuxeo claims to be the most performant content services platform on the market, due in large part to their move to a NoSQL back-end.
Alfresco never did anything serious around NoSQL but it is interesting to note that one of their partners did. Chicago-based Technology Services Group made a big investment in Hadoop back in 2015, essentially offering it as a back-end alternative to Documentum and Alfresco as part of their OpenContent offering. TSG has multiple clients on Hadoop including a not-for-profit, a pharmaceutical firm, and a nuclear power plant. According to TSG’s founder and president, Dave Giordano, his clients running the Hadoop-based repository couldn’t be happier. Now the firm has added Amazon’s DynamoDB as an additional back-end repository option.
TSG is providing Hadoop and Dynamo as back-end options for their business solutions. But what about something developers can take advantage of when building their own solutions? Some colleagues and I did some experimentation a couple of years ago around building a simple content repository using DynamoDB for metadata storage, Amazon S3 for object storage, and Lambda for the API and it worked pretty well.
Sometimes all you really need is a place to store digital objects and a place to manage metadata about those objects. You don’t need a full ECM platform installation to do that. When TSG sells OpenContent it is the solution they are selling–the back-end is just an implementation detail.
Which brings me back to that 2010 blog post. In addition to predictions about NoSQL eventually being a featured architectural component of content management systems, I also wondered what the rise of NoSQL meant for Alfresco:
“Where does that leave Alfresco? It seems their positioning as a developer-focused, “Internet-scale” repository ultimately leads to them competing directly against NOSQL repositories for certain types of applications.” — Jeff Potts, 2010
I actually worked at Alfresco around this time. Part of my job was to reach out to developers to convince them to build their solutions on top of Alfresco. The broader developer audience was not on board. A big reason is that those developers were already using things like MongoDB and CouchDB for JSON stores. These were much lighter, more flexible, and far more scalable. There is just no comparison between native JSON repositories and Alfresco by these measures.
Several years later, I still get inquiries from people that can be summarized as, “We’re thinking of building this custom solution that has nothing to do with managing office documents but does need an unstructured repository. Do you think Alfresco would be a good fit?”. The answer is usually no. This isn’t a knock on Alfresco–it’s just about purpose-of-fit. If you don’t need versioning, check-in/check-out, online editing, or transformations, why pay the overhead?
So, to answer the question from my past self about where that leaves Alfresco, it was never really a contest. Developers adopted technologies like MongoDB and others in droves. Rather than a light-but-scalable piece of infrastructure that devs routinely incorporate into larger solutions, Alfresco is a full-fledged platform–with all of the good and bad that entails–whose price tag and footprint demand serious justification before being implemented.
What this means for Alfresco today
Back when I wrote the NoSQL blog post, Alfresco thought its most likely entry point was via developers who needed a repository, grabbed Community Edition, and eventually converted into paying customers. But the very broad population of developers have other technologies–not Alfresco–top of mind when it comes to building custom applications. People are continuing to download Alfresco, but I think the “who” and “why” has shifted.
If you look at what Alfresco has done lately, the 6.0 and 6.1 releases are mostly about customization and deployment. The Application Developer Framework (ADF), the new Docker containers and Helm charts in 6.0, and SDK 4.0, which is heavily Docker-based, are all welcome additions.
Absolutely, the platform has to be easier to extend, customize, and deploy, so I’m glad to see that being addressed, but my customers don’t actually care as much about those things. There have been some great new end-user features added recently, such as the Search and Insights Engine and the Digital Workspace, but more are needed if Alfresco wants to reclaim its “visionary” status.
Alfresco is not in the “content repository” market. Developers can create a schema-less, scalable, replicated repository easily with NoSQL and other technologies. Scoff at the buzzwords if you want, but I think “Digital Business Platform” actually describes Alfresco really well. The key is that a “Digital Business Platform” isn’t for developers, although they need to extend and customize it. The platform is for business users.
At DevCon, we’re going to see a ton about ADF and Docker, and those topics are important to the DevCon audience. But my customers are looking for innovative, business-friendly features ready to use, out-of-the-box. It may sound strange coming from me, but those end-user innovations are what will keep Alfresco relevant and appealing to the market they are actually in.
Photo Credit: Mirror, by Vadzim Vinakur, CC BY-NC 2.0
One of my clients came to me with a problem: Despite being a much-admired Fortune 500 company that leads its competitors in the travel industry in customer satisfaction and profitability, their web site, through which the vast majority of their revenues flow, was still mostly static. That by itself is not a huge problem, but they felt like they weren’t able to target content based on their customers’ needs and interests as well as they could with a more dynamic content engine.
It just so happened they were about to re-implement their site from mostly server-side to mostly client-side which is a huge undertaking. They figured that would be a pretty good time to add a dynamic content service to the mix, so they called me.
From Static to Dynamic
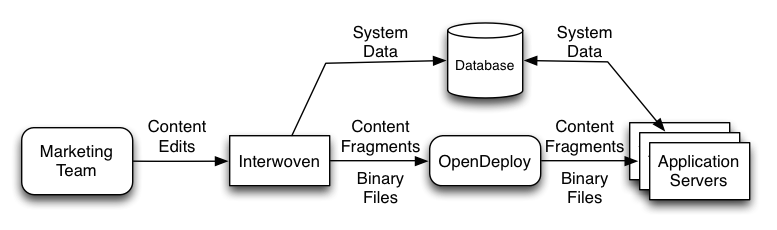
The diagram below depicts the high-level setup before the introduction of the content service.
This is pretty standard for sites like this. The Marketing Team edits content in a Content Management System (CMS), which in this case is Interwoven. Through various processes, binary files (mostly images), system data (things like lists of destinations and hotels), and content fragments are published out of Interwoven to destinations accessible by the e-commerce application.
A content fragment is literally a piece of content. It might be a promotion of some sort. Or it could be some text that gets used as part of a banner. The challenge using this setup is that content fragments are static files that live on the file system. If you want to show a different fragment based on something you know about the user you have to generate every permutation you might want ahead-of-time, publish them all, then use logic in the application to decide which one to use.
One obvious way to address this is to publish content fragments in a relational database and then code the front-end app to query for the right content. That wasn’t appropriate here for a few reasons:
The front-end is being migrated to a collection of Single Page Applications (SPA’s) written in JavaScript. It’s easier for those pages to call a RESTful API to get JSON back. Yes, you could still do that with a relational database and a service tier, but the client was looking for something a little more JSON-native.
The structure of the content changes over time. We wanted to be able to accept any kind of content fragment the Marketing Team or SPA developers could think of and not have to worry about migrating database schemas.
The anticipated style of queries needed to find appropriate content fragments was more like what you’d expect from a search engine and less like what you might put in a SQL query–we needed to be able to say, “Here is some context, now return the most appropriate set of content fragments for the situation,” and be able to use relevancy scoring to help determine what comes back.
So relational databases were ruled out in favor of document-oriented NoSQL repositories. Ultimately, Elasticsearch was selected because of its ease of clustering, high performance, unified REST API, availability of commercial support, and add-ons such as Shield, Marvel, and Watcher that make it easier to integrate with the rest of the enterprise.
Introduction of a Content Delivery Service
The first thing we did was stand up an Elasticsearch cluster, load some test data, and beat the heck out of it (see “Using JMeter to Test Elasticsearch“). Once we were satisfied it would be able to handle more than the expected load we moved on to the service.
The Content Delivery Service sits between Elasticsearch and the front-end applications. Its purpose is to abstract away Elasticsearch specifics and to protect the cluster by providing a simple, read-only REST API. It also enforces some light business logic such as making sure that only content that is currently effective according to its publication and expiration date is returned.
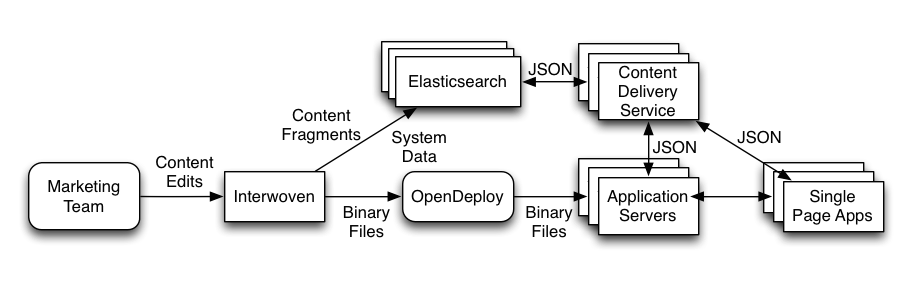
The diagram below shows the content infrastructure augmented with Elasticsearch and the content delivery service.
As seen in the diagram, Interwoven is still the source of record and the primary way Marketing manages their content. But now, content fragments and system data are published to Elasticsearch. The front-end Single Page Apps ask the Content Delivery Service for content based on some set of context. The content is returned as a collection of JSON objects. The SPAs then take those objects and format them as needed.
Content Objects are Pure Content
A key concept worth emphasizing is that a content object is pure content. It contains no markup. It might have some properties that describe how it is expected to be used, but it is completely lacking in implementation. This has several benefits:
Content objects returned by the Content Delivery Service can be used across any and all channels (such as mobile) rather than being specific to a single channel (such as web).
Within a given channel the same object can have many different presentations.
Responsibilities are cleanly separated: The content service provides content. The front-end applications style and present the content for consumption.
This was a bit of a departure from how things used to be done. In the bad old days presentation was always getting mixed up with content which severely limits reuse.
Micro-services Provide Administrative Features
I mentioned earlier that the Content Delivery Service is read-only. And in my previous diagram I showed Interwoven talking directly to the Elasticsearch cluster. In reality, we don’t let anyone talk directly to the Elasticsearch cluster. Instead, all writes have to go through the Content Management Service. This ensures that we know exactly what is going into the cluster and who is putting it there.
The other role the Content Management Service plays is JSON validation. When new types of content objects are developed we use JSON Schema to codify the structure. When a person or system posts a content object to the Content Management Service, the service validates the object against its JSON Schema before storing it in Elasticsearch.
In addition to the Content Management Service we also implemented a Scheduled Job Service. As the name suggests, it is used to perform administrative tasks on a schedule. For instance, maybe content needs to be reindexed from one cluster to another in a lower environment. Or maybe content needs to be fetched from a third-party and written to the cluster. The Job Service is able to talk to either the Content Management Service or Elasticsearch directly, depending on the task it needs to execute.
All of the administrative services are independently deployed web applications that sit behind an API Gateway. The Gateway leverages the Netflix Zuul Proxy. It is responsible for authenticating against LDAP and creating a shared session in redis. It gives the content admin team a single URL to hit and isolates authentication logic in a single place.
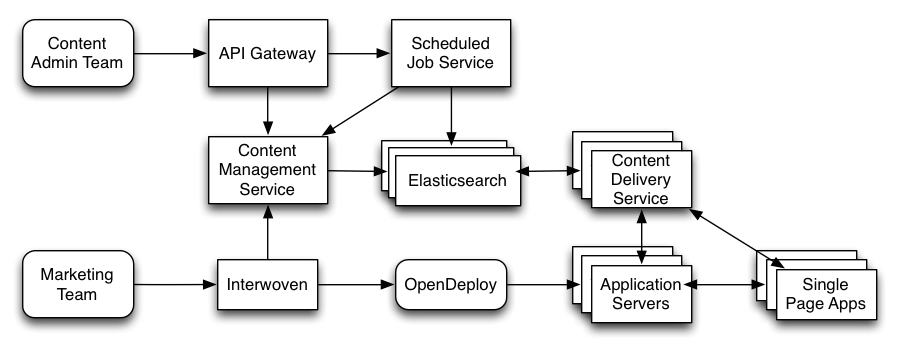
The diagram below shows the fully-realized picture.
A few key components aren’t on the diagram. We use Shield to protect the Elasticsearch cluster. Shield also makes it easy to configure SSL for node-to-node communication and provides out-of-the-box LDAP integration. With Shield we can map LDAP groups to roles and then grant roles various privileges on our Elasticsearch cluster and its indices.
We use Watcher to monitor cluster health and job failures that may happen in the Scheduled Job Service. The client has their own enterprise alerting and monitoring solution, but Watcher gives the content management team a flexible, powerful tool for keeping track of things at a level that is probably more granular than what the enterprise ops team cares about.
Ready for the Future
With Elasticsearch and a few relatively small services on top of that, this travel giant now has what it needs to provide its customers with a more customized online experience. Content can be targeted to the users it is most appropriate for using any kind of context the Marketing team can come up with. As the front-end commerce app evolves, new types of content objects can be added easily and be served to the front-end with no schema or service changes required. And it’s all built on commercially-supported open source software.
Cloud CMS announced today that it has added support for CMIS. This is a nice addition for all sorts of reasons, but near the top from Cloud CMS’s perspective is that it makes it easier to migrate content from existing solutions into the Cloud CMS repository.
Back in November I did a series of reviews on content-as-a-service providers. One of my posts was on Cloud CMS. The post assumes you are looking for hosted content-as-a-service and shows how Cloud CMS compares to other cloud offerings.
What I think we’re going start seeing more and more, however, are people who might consider Cloud CMS as an alternative to traditional on-premises ECM vendors like Alfresco, Nuxeo, Documentum, and Microsoft. Although Cloud CMS was originally built to be a hosted, content-centric, back-end for mobile and web applications, it can just as easily function as your hosted intranet or document management repository.
With custom content models, event triggers, and custom workflows, you may find that the only difference between Cloud CMS and your current on-premises document repository is that you don’t have to worry about software or hardware installation and upgrades any longer.
Considering Cloud CMS as an alternative to traditional players may make sense when:
A 100% cloud-native solution is preferred. While Cloud CMS could be run on-premises it is certainly built to be hosted on your behalf. Plus, one of the benefits of letting Cloud CMS run, upgrade, and scale your repository is so you don’t have to.
Customization is important. Some of the traditional vendors have made cloud add-ons for their products, but they then lock down the content model and the user interface so that it cannot be customized. Cloud CMS offers the benefits of hassle-free operations while maintaining your ability to customize it to meet your exact requirements.
Budget is constrained. Clients who need enterprise-grade features and the peace of mind that a support contract brings but can’t justify the high cost of a traditional vendor’s enterprise license may find Cloud CMS to be a lower-cost alternative. Rather than licensing by the seat or the server, Cloud CMS cost is based on how and how much you use the system.
Clients who have very straightforward needs (simple file sync and share, for example) will probably choose something a little more utilitarian, like Google Drive, Box, Dropbox, or Amazon Zocalo. And, despite Cloud CMS recently having undergone an extensive security audit, I know some clients may still be reluctant to move to the cloud. Everyone else, though, should take a hard look at Cloud CMS.
The next vendor in my Content-as-a-Service (CaaS) round-up is Cloud CMS. If you missed my overview of the CaaS market, you might want to read that first.
Cloud CMS has been around since 2010. It was founded by Michael Uzquiano, formerly of Alfresco, Epicentric, and Vignette. This year they brought on a new CEO, Malcom Teasdale, who, prior to joining Cloud CMS, ran Rothbury Software, an Alfresco partner that was ultimately purchased by Ixxus. Malcom spent some time at Interwoven earlier in his career. So these two have a lot of content management experience and that’s evident in their product. (Disclosure: I’ve known Michael and Malcom for several years but I do not currently have a business relationship with Cloud CMS).
My CaaS overview described functionality you’ll find in all CaaS offerings. Similar to my posts on Prismic.io and Contentful, in this post on Cloud CMS I’ll focus on some select areas of the Cloud CMS offering:
User interface for content authors
Creating content types
Working with content via the API
Security
Pricing
Cloud CMS is an extensible platform with a long list of features. This is more than just a place to stick content and an API to get it back out–this is a full-featured CMS that happens to be running as SaaS in the cloud. But I’m primarily interested in it for its ability to act like a CaaS offering, which to me means a more pragmatic, stripped down approach to content management, so this review is going to ignore a lot of the Cloud CMS features that go beyond that. Perhaps I’ll come back to those in a future blog post.
User Interface for Content Authors
Before I describe the Cloud CMS user interface let me tell you a little about how Cloud CMS stores content. A Cloud CMS account has one or more repositories. How you use your repository is up to you–you might have one repository per project, for example.
Within a repository there are one or more branches. A branch works just like it does in source code control–it is a view of the repository. Each repository has a “master” branch, but you can have as many branches in a repository as you want. Branches can be areas where individuals work on content in isolation, or they can be for teams. Branches can never be deleted.
Within a branch are one or more changesets. Adding content to a branch (or making any change) takes place against a changeset–you’re never actually changing anything that was written previously.
And, finally, at the object level you have nodes. Everything in Cloud CMS is stored as a node. If you have a blog post, that’s a node. If your blog post points to an image, the image is also node. All nodes are typed. There are out-of-the-box types but you can also define your own. I’ll talk more about that in a bit.
Cloud CMS provides a web user interface that helps teams organize content creation built around the notion of projects. For the most part, your users see your repository through the lens of a project. They don’t have to understand the underlying structure of the Cloud CMS repository.
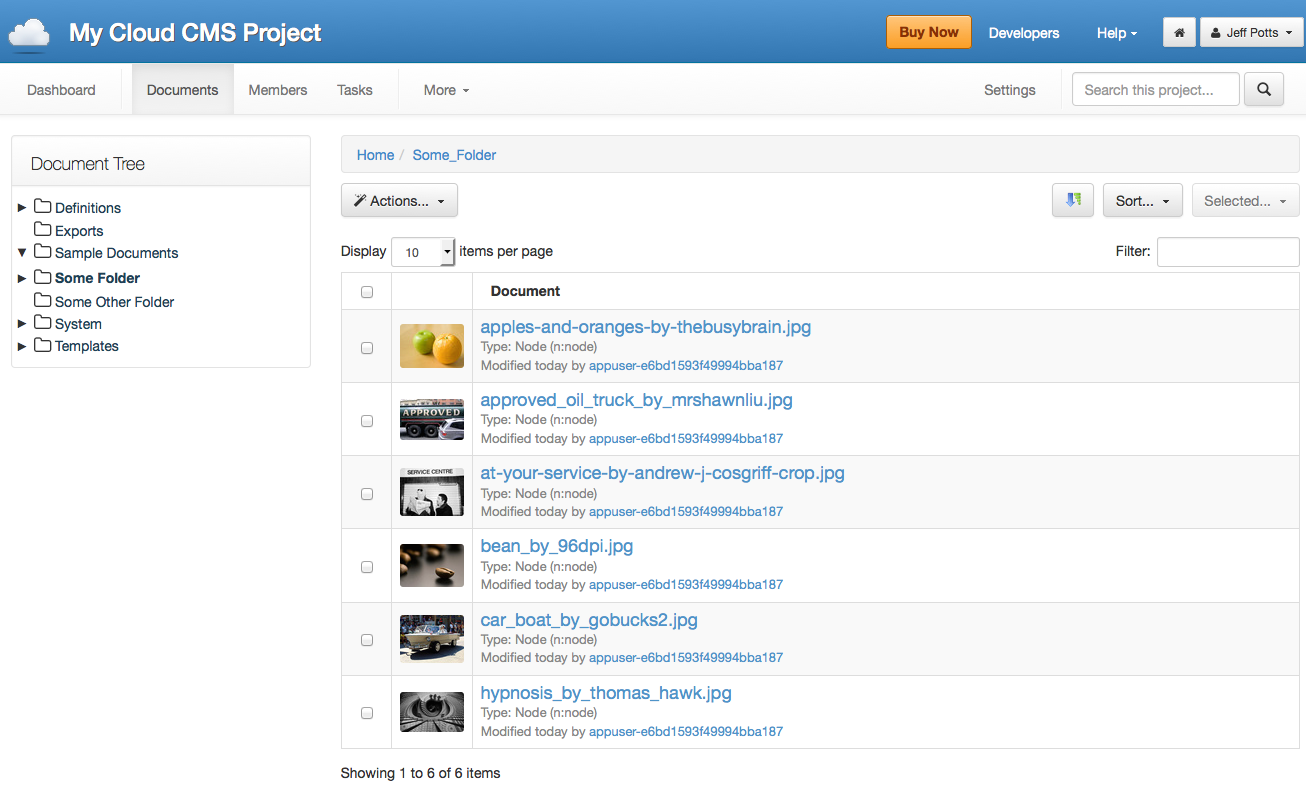
The first thing you see when logging in to Cloud CMS is a dashboard. From here you can manage your projects, tasks, members, and workflows. For my review I created a project called “My Cloud CMS Project”.
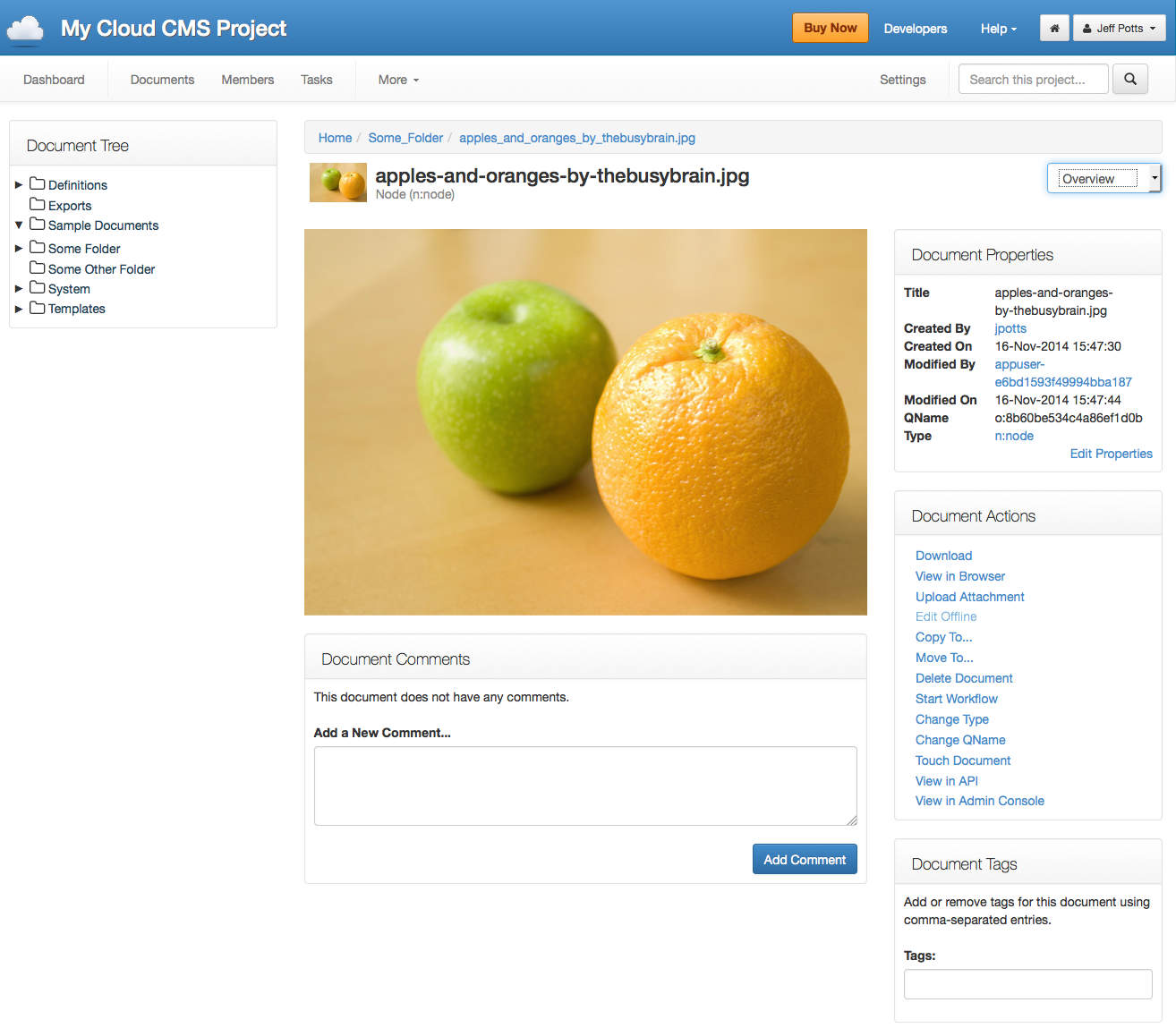
Drilling into the project displays the project’s dashboard. Clicking on Documents shows a hierarchical view of folders and documents. Multiple files can be dragged-and-dropped which triggers an upload to the folder. As you can see in the screenshot below, thumbnails are automatically created and displayed in the document list.
Clicking a specific document opens the details page for that object where users can edit the properties of the object, make comments, assign tags, start workflows, and perform a number of other actions.
So that’s how content authors manage content in Cloud CMS. Let’s take a look at how the content model is defined.
Creating Content Types
Content Type definitions are created using JSON Schema. You can define types using either the Cloud CMS UI by typing your JSON Schema into a web form, or by using the API. I really like the ability to define a content type simply by typing the JSON Schema that defines it. Of course, the trade-off is that you have to know how to define a type using JSON Schema. Fortunately, there is documentation that can help.
Content modeling in Cloud CMS is much more advanced than what I’ve seen in other CaaS offerings. Three examples of that are: hierarchical content models, aspect-orientedness, and role-based form definitions.
The first one, hierarchical content model, is easy to grasp: Your types can inherit from parent types. This can potentially save you time setting up your content model if your types lend themselves to being organized in a hierarchy.
The second one requires a little more explanation: aspect-orientedness. A content model is aspect-oriented when it has the ability to define bundles of properties that can be “attached” to objects, regardless an object’s underlying type. In Alfresco these are called “aspects”, in CMIS these are called “secondary types”, and in Cloud CMS these are called “features”.
For example, you might have a set of metadata that you want to track for anything that is “client-related” like the client’s name, industry, size, and primary contact. In Cloud CMS you define that set of metadata as the “client-related” feature, and then any object can become “client-related” just by adding the client-related feature–the bundle of properties having to do with a client–to the object.
The third advanced content model-related feature in Cloud CMS is role-based forms. When you create instances of a content type, Cloud CMS looks at the schema and generates a default form, similar to how other CaaS offerings work. What’s different is that Cloud CMS allows you to define multiple forms for the same content type. You can tie forms to specific roles so that different people see different authoring forms depending on their role. This is helpful when you have different types of people who need to edit the same content–you can use role-based forms to structure the form the way it makes the most sense for each type of user.
By the way, like content type definitions, form definition is also JSON-driven. Cloud CMS leverages the open source AlpacaJS forms engine into their product, which you might want to consider for your own projects, even if you don’t need Cloud CMS.
Working with Content via the API
Cloud CMS can host your application for you. This makes it nice for people who are looking for a one-stop shop for their content-centric mobile and web applications because you don’t need separate services for your content and your app. If you look back at the project dashboard screenshot I showed earlier you’ll see an example–I’ve created an application called “demo”.
What wasn’t obvious to me initially is that even if you are going to host your application elsewhere, you still need to create an application, and within that, a deployment. That’s where you’ll find the API keys needed to work with the API.
In addition to the API keys you’ll need to know your repository ID (which you can get from the Cloud CMS admin console). If you are going to fetch content from anything other than the master branch you also need the branch ID. Once you have that, querying for nodes is straightforward, as shown in this gist:
Under the covers, Cloud CMS is running MongoDB and Elasticsearch. So when you query for Nodes, you’re using Mongo. When you’re searching the full-text of your nodes you’re using Elasticsearch.
Everything in Cloud CMS is stored in JSON so creating content is as simple as calling createNode and passing in JSON for the property values:
Every object in Cloud CMS can have an ACL and child objects can inherit ACLs from their parents. There are out-of-the-box roles you can use in those ACLs, including: Connector, Consumer, Contributor, Editor, Collaborator, and Manager. Unfortunately, to set permissions on an object you have to switch from the project user interface to the administrative user interface. Still, this is the only vendor in the round-up offering object-level permissions.
Pricing
Cloud CMIS offers a free 14-day trial. After that you have to switch to one of four monthly plans:
Starter: $20/month. Limited to a single project and email support.
Platform: $200/month. Unlimited projects and email support.
Enterprise: $2400/month. Private cloud with an on-premises option
The ability to run the entire stack on-premises is an interesting option for those not ready for the cloud although I haven’t explored how practical that really is for Cloud CMS.
The usual caveats apply to pricing here. Like other CaaS offerings, Cloud CMS places limits on total storage space and data transfer so look at the details to make sure you understand what this will cost you each month.
Overall Impressions
Cloud CMS is a full-featured platform for content management. Where some startups focus on the minimum viable product, Cloud CMS has gone for a kitchen sink approach that approximates the functionality you might expect in more mature, on-premises ECM offerings. Cloud CMS can even be the platform that runs your application, if that’s what you need.
Content management professionals will appreciate the advanced content modeling and forms features, which is just one example of functionality that reflects the founders’ ECM industry heritage. The flip-side of that coin, however, is the complexity also reminiscent of those systems. The documentation and tutorial videos help but there is a learning curve here.
Cloud CMS can compete against CaaS players like Prismic.io and Contentful as well as established ECM vendors like Alfresco and Documentum. Compared to other CaaS players it has much richer functionality, but it is also more complicated to use. To compete against them successfully Cloud CMS may need to further streamline the UI so that users can harness that power without being overwhelmed by other features.
Compared to established vendors like Alfresco and Documentum, Cloud CMS offers a hosted system running in the cloud with a similar feature list while maintaining the ability to customize the platform. Customers looking to move to the cloud may find an easier migration to Cloud CMS than to one of the newer CaaS players. In this respect Cloud CMS also competes with other traditionally on-prem document management offerings now offered in the cloud like Hippo onDemand and Nuxeo Cloud.
With two ECM veterans at the helm and impressive functionality it will be interesting to watch Cloud CMS go after one or both of these markets.
It’s time for the next vendor in my Content-as-a-Service (CaaS) round-up. In this post I’ll be taking a look at Contentful. If you missed my overview of the emerging CaaS market you might want to take a look and then come back.
Contentful came out of beta to be generally available in May of 2014, so it is the youngest vendor of the three in my round-up. The company is based in Berlin and has a number of well-known clients including EA, Disney, Viacom, Asics, Nike, Playboy, and McAfee.
My CaaS overview described functionality you’ll find in all CaaS offerings. Similar to my post on Prismic.io, in this post on Contentful I’ll focus on the areas that typically differentiate one CaaS offering from another, namely:
User interface for content authors
Creating content types
Working with content via the API
Security
Pricing
Finally, I’ll wrap up with my overall impressions and takeaways.
User Interface
In Contentful you have one or more “spaces”. You can think of a space as a repository. It’s a collection of “entries”, which are instances of content types, and “assets”, which are file-based assets like images. In addition, each space has its own users, roles, and API keys.
When you log in to Contentful you’ll be sitting in one of your spaces (the first one in the list). The Contentful user interface is clean and quite minimal. It’s easy to get going quickly because you have a limited function set. You can define your content model, manage entries, manage assets, or manage your API keys and that’s about it.
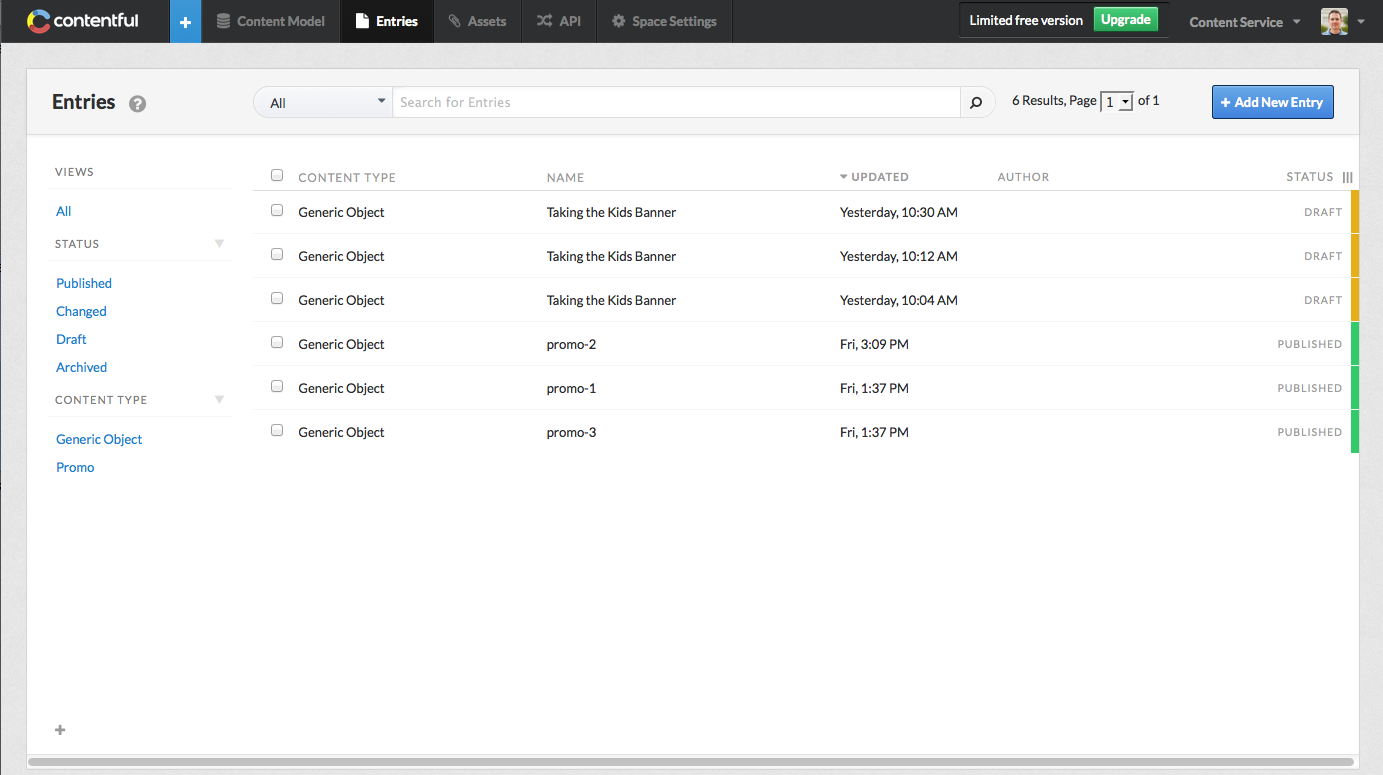
Options for organizing lists of entries and assets are limited to filtering based on status (Published, Changed, Draft, Archived), content type (for entries), and file type (for assets). There is a saved search feature and saved searches can be organized into folders. But, there is no notion of hierarchical content storage.
This minimalistic approach to content management is what I characterized as a Good Thing in my Content-as-a-Service overview.
Content Types
Every content management system has a way to describe the data stored in the repository which is referred to as a “content model”. In Contentful, each space has its own content model which is simply a set of content type definitions. A content type is a set of typed properties. There are property types you’d expect, like text, date, number, decimal number as well as “pointer” types that reference other objects in the system, where those objects are either entries or file-based assets.
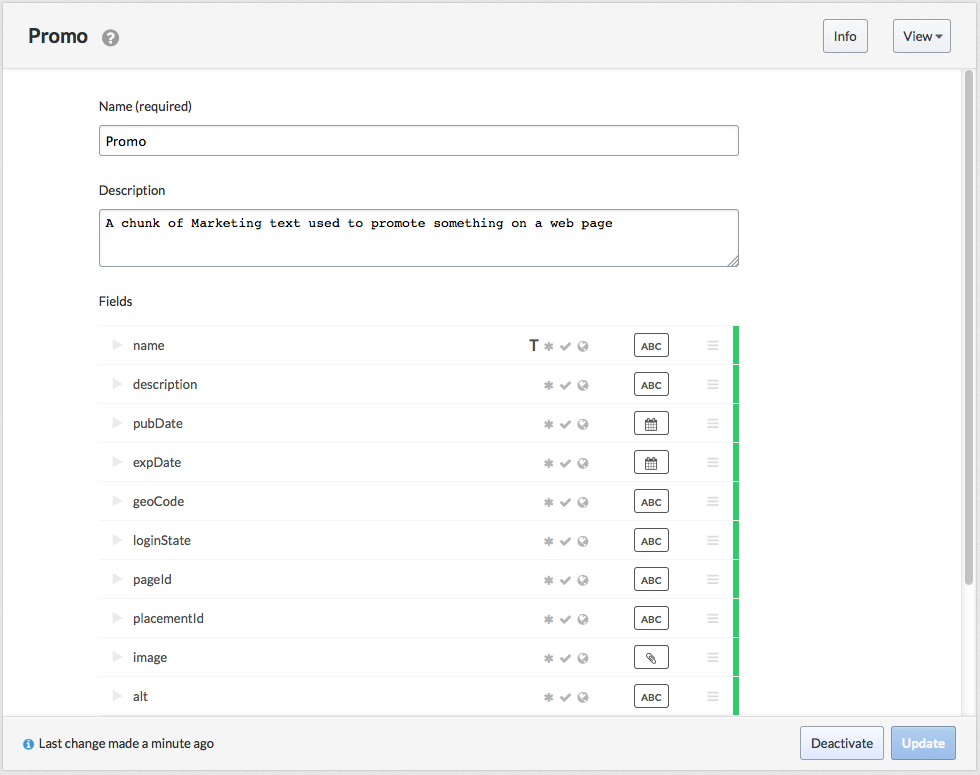
For example, the screenshot below shows a Promo content type I created. It has a name, a description, and a set of fields such as pubDate, geoCode, image, alt, etc. In the case of the image field, it points to a file-based asset.
Unfortunately, there is no support for cross-cutting concerns (aspects) so if you want to repeat property definitions across types you have to do that manually. For example, a type called “Cat Picture” and a type called “Dog Picture” might both have “height” and “width” properties. In Contentful, you have to repeat similar properties across type definitions.
On a related note, there is no way to clone or copy content types in the user interface. If you have two similar content types you have to re-do the property sets in each one or use the Contentful content management API to do this.
Managing your content model in the Contentful UI takes way too many clicks. I much prefer the approach other CaaS offerings take where you edit the content type definitions using JSON rather than the point-and-click approach. The nice thing with Contentful is that you can use the API for everything, including defining your content model–you don’t have to use the UI at all if you don’t want to.
One thing to watch out for: If you want to change a field on a content type (like maybe change the type of field) you have to deactivate the content type first. That’s not such a bad thing until you realize you cannot deactivate a content type without first getting rid of the instances of that content type. This could be a challenge once you go to production, so make sure you are happy with your content model before you get too far down the road.
Working with content via the API
Content can either be “published” or “draft”. The API keys you generate for a space can either be “production” or “preview”. The production URL and access key can only fetch published content. The preview URL and access key will see everything.
The Contentful Content Delivery API lets you fetch content by space which can be further filtered by query terms that will be AND’ed together. There was not an obvious way to OR query terms.
If you’d rather, Contenful offers client libraries in Java, JavaScript, Objective-C, Swift, and Ruby.
Here is a gist that fetches content using JavaScript:
If all you need to do is fetch content from Contentful, you’ll stick with their Content Delivery API. To create, update, or delete content, use the Content Management API.
Note that content is initially created in draft mode. You must publish the content if you want it to be retrievable via the “production” content delivery API.
I should mention that Contentful also offers a sync API, which is particularly useful for mobile applications.
Security
In Contentful, everyone belongs to one or more Organizations. Organization owners can create spaces and can invite users to a space. Users can be editors (edit all content) or developers (edit all content, manage API keys). Space admins can create new content types. The UI shows a “custom role” but this article says that custom roles will be implemented for the enterprise offering at some point in the future.
Contentful also makes it easy for agencies or consultants to administer an organization on their client’s behalf while the client remains the main contact for billing purposes.
Pricing
Contentful offers the following plans:
Free plan which is limited to 3 users, 3 spaces, and 1,000 objects
Plus plan for $99 per month which includes 5 users, 5 spaces, and 5,000 objects
Pro plan is $200 per month for up to 10 users, 10 spaces, and 10,000 objects.
Most of my clients would probably need the “Enterprise” plan which could cost anywhere between the low thousands to the tens of thousands of dollars per month depending on exactly what is needed.
Also, be aware that Contentful, like other CaaS vendors, places limits on additional things such as API requests, API bandwidth, and API keys. These and other details may change so take a look at the pricing page (click “Compare Plans” for the expanded details) to be sure.
Overall Impressions
Contentful is an extremely basic offering in terms of both the user interface and the capabilities of the underlying platform. But the simplicity of the offering is precisely what makes it so attractive. Developers will appreciate the “API-first” approach to content management, and without a lot of extraneous sub-systems getting in the way, they’ll be able to develop a solution quickly, and then let content authors manage the content with the easy-to-use interface. Contentful’s stripped down, pragmatic approach to content management is a category-defining building block you can use to create really cool content-centric solutions.
Today I’m going to take a brief look at Prismic.io. Prismic.io is one of three commercial Content-as-a-Service (CaaS) vendors I’m reviewing as part of my CaaS round-up. If you missed my overview of the emerging CaaS market you might want to take a look and then come back.
Prismic.io was founded by Sadek Drobi, one of the co-creators of the Play framework, and Guillaume Bort, one of the Play lead developers. It launched in early October, 2013.
My overview talked about the kind of functionality you’ll find in all CaaS offerings. In this post on Prismic.io I’ll focus on the areas that typically differentiate one CaaS offering from another, namely:
User interface for content authors
Creating content types
Working with content via the API
Security
Pricing
Finally, I’ll wrap up with my overall impressions and takeaways.
User Interface: Let me show you to your room
Your Prismic.io account starts out with a sample repository called Les Bonnes Choses (The Good Stuff) and some sample content within that. The repository and sample content powers a sample web app for a fictitious pastry shop.
When you first log in to Prismic.io a dashboard lists the Les Bonnes Choses repository and any other repositories you’ve created. A quick side-note on repositories: When creating a new repository I was forced to pick a name no one else had taken. The repository name is used as a sub-domain under prismic.io, so I see why it has to be unique, but this seems like an odd choice for a service I’m sure the founders are hoping will grow wildly.
Anyway, clicking on a specific repository takes you into that repository’s “writing room”, which is the primary interface for not only authoring content but also configuring your repository’s various settings.
The writing room UI is certainly the most polished of any of the CaaS vendors I reviewed. While it looks great, I feel like the fly-in/fly-out animation is a bit over-used and many of the icons are un-labeled. The UI also uses colors to indicate status, but the meaning is not obvious initially.
The overall organizational model is activity-centric rather than asset-centric. If you’ve got a team of people pushing out content in a rather flat hierarchy this will probably work well. If you like a more traditional list-of-assets-in-a-nested-folder hierarchy you’ll have to adjust. The “Live Now”, “Your Documents”, and “Favorites” help filter the list of content.
Releases provide snapshot capability
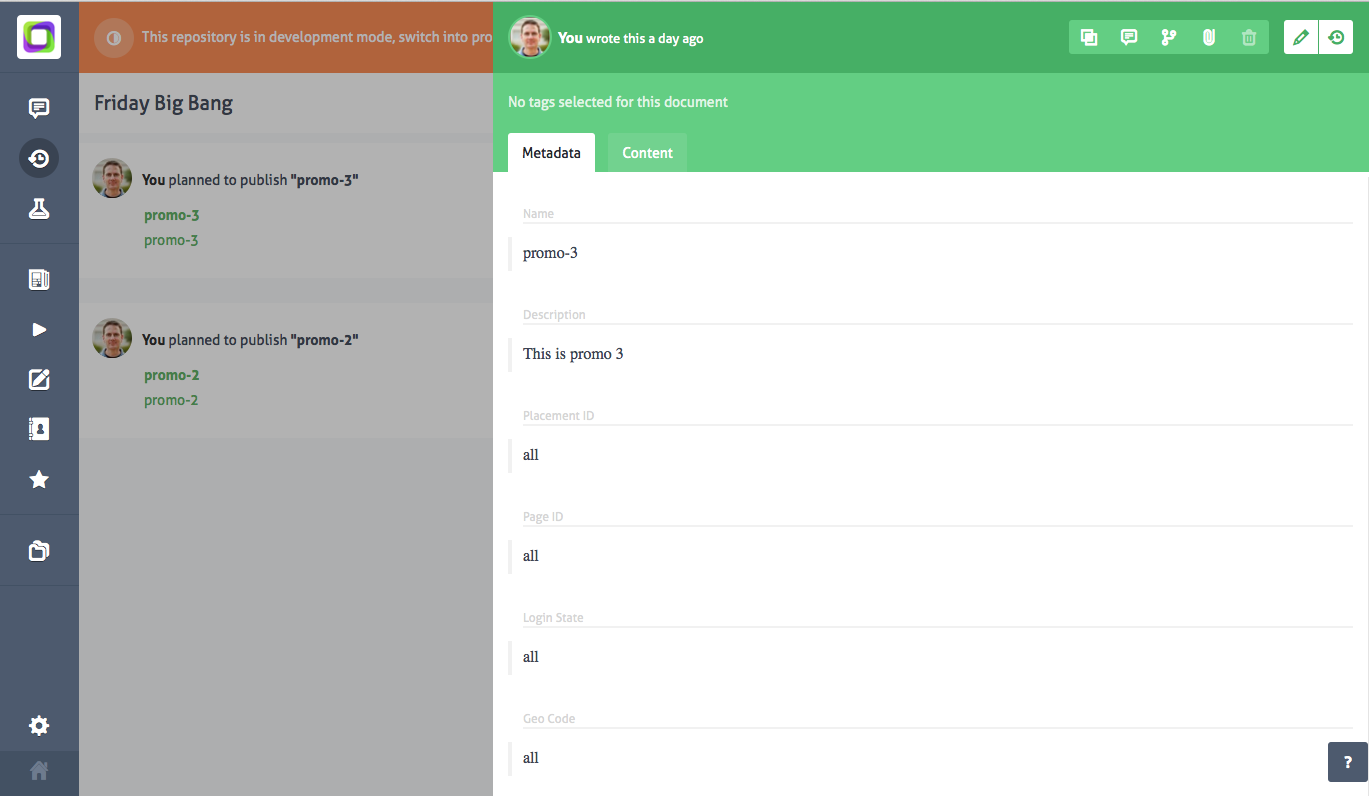
A helpful concept in Prismic.io is the “content release”. This gives you the ability to plan releases ahead-of-time. When your content authors write content they can publish it to a release. When the release is published, all content associated with that release goes live. You can control who can access to-be-published content in the API settings.
Creating content types
In Prismic.io, content types are called “Document Masks”. Document masks are defined via the Prismic.io UI by writing JSON that describes the mask. For example, here is a snippet from the Blog Post document mask:
Notice that there is an object called “Blog Post” and an object called “Metadata”. These are rendered as tabs in the writing room UI. You can segment your document mask definitions however you see fit. Within the top-level object there are one or more fragments, each of which has a name, like “author”, a fieldset, a type, and a config.
Looking at the “author” config you can see that it is possible to add references to other documents in the repository. In this case the association is between the blog post and an author object. Elsewhere in the blog post example are similar links to “related posts” and “related products”.
I like that the content type definitions are expressed as JSON. It’s a lot easier to work with definitions in this way than with a UI-driven approach, especially when the content type definition language is fairly rich, as it is here.
Another nice feature of the document mask editor is the ability to quickly preview what the form will look like in writing room.
Collections and Bookmarks
Document masks define the type of documents your content authors can create. Prismic.io also gives you the ability to define collections and bookmarks.
You can think of a collection as a saved search. A collection defines a set of filters (document masks and/or tags). Content authors can then navigate to content by clicking collection names in the writing room. In fact, aside from the filters I mentioned earlier, collections are the only way to organize content.
Your front-end can use the API to get the documents matching a collection by specifying the collection name rather than building the query from scratch. I’ll show you an example of that in a minute.
A bookmark is a collection for a single document. It is kind of like an alias. Suppose you are building an app that needs to promote a “deal of the week”. The deal might change from time-to-time. One way to implement this would be to create a bookmark named “dealOfTheWeek” and point it to a document for this week’s deal. The front-end app can always ask for the same bookmark, but the object it points to can change as needed.
Fetching Content via the API
There are multiple client-side libraries you can use to work with content in Prismic.io including JavaScript, Python, Java, Ruby, .NET, PHP, and Scala. You can get more info from the Prismic.io developer page.
Here’s an example showing how to get the documents in a collection named “blogPosts”:
In the bookmark example you can see that once the document ID is fetched from the bookmark I constructed a query against the “everything” collection using the ID. This barely scratches the surface of what’s available in the query language–check out the developer docs to learn more.
One extremely disappointing thing about the Prismic.io API is that it is read-only. Yes, you read that right. Prismic.io is a content service that only lets you read content via the API, not create it.
The lack of a write API means that if you have existing content that you want to move to Prismic.io, there’s no way to do that short of hiring a bunch of temps and re-keying it into the system. Potentially worse, if your content originates from some other system and you want to use Prismic.io for delivery, there’s no way to do that either. And of course if you have user-generated content you need to persist from the front-end, you’ll have to write to some other service.
I suspect that a year from now we will all agree that a write API is table stakes for a viable CaaS offering and Prismic.io either will have fixed it or they will have relegated themselves to a microscopic corner of the market focused on tiny, greenfield, content silo projects. We shall see!
Security
By default, the API requires an OAuth token. Per repository, you can change that. For example, you might make it so that the API can fetch content from the “master” release without a key, but fetching content from future releases requires a token. Or, you can make access completely open.
Pricing
With Prismic.io, development is free. You don’t pay until you go to production. There are three paid plans available: Simple gives you all of the featues, but is limited to three users for $7/month. Team gives you unlimited users for $40/month. Enterprise gives you an SLA and a private cluster but you’ve got to negotiate pricing.
Something that’s pretty cool for all of my open source friends is that if you make your content available under the Creative Commons 4.0 license, you can use a Simple plan for free.
These plans, pricing, and details may change, so take a look at the official pricing page.
Overall impressions
The lack of a write API for programmatic content creation makes Prismic.io a non-starter for anyone having anything more than the most modest requirements, particularly in cases where there is a large volume of pre-existing content or when other systems need to write into the content store.
If you have the luxury of starting with zero content and all of your content will be created by humans using the snazzy Prismic.io user interface, then it is worth considering.
Prismic.io certainly has the most helpful developer on-ramp of any of the solutions I looked at with lots of client libraries, good examples, decent documentation, and useful starter apps. And I also liked their “free while you are developing” model, which makes it easy for teams to get started building their real solution, rather than a scaled-down PoC.
If Prismic.io puts a write API in place they’ll be a strong CaaS contender.
There is an interesting new market emerging in the world of content management: Commercially-hosted Content-as-a-Service (CaaS). These are vendors who provide a service your applications can leverage for content management. Different than, “Hey look, we’re running our old school CMS in the cloud!”, CaaS is singular in focus and free from the feature bloat and operational complexity typical of the CMS your parents probably used.
At a minimum, CaaS vendors provide the following:
a hosted repository,
some mechanism for defining the types of content you need to manage,
a RESTful API to get content and static assets into and out of the repository,
a web-based user interface for managing content,
web hooks for taking action when content changes,
CDN integration for efficiently serving up static assets, and
an up-time and performance SLA.
You then build your web site or mobile app using any technology that suits your needs and fetch content as JSON using the API.
The best approach is to use the service to manage reusable, presentation-agnostic chunks of content. Metadata associated with the content chunks can then be used to make it easier to fetch the content for a variety of contexts. Because it is free of presentation the content can be more easily shared and reused across properties and channels.
Why not Drupal or WordPress?
CaaS vendors do not directly compete with full-featured platforms like Drupal or WordPress. There are Drupal and WordPress modules that add RESTful APIs on top of those platforms, so you could build a web or mobile site that is completely de-coupled from your Drupal back-end. Conversely, you could build a web site on top of a CaaS vendor’s service that had the same look, feel, and features of a site built with a traditional CMS. But both of those examples miss the point of CaaS which is, in a word, simplicity.
I’m not saying products like Drupal and WordPress are hard to use. On the contrary, you can install those tools and have a great looking site up-and-running in minutes. I’ve run this blog on WordPress for years and I am extremely happy with it. And sites like wordpress.com and Drupal Gardens take the hassle out of setting up your own server.
When I say the key to CaaS is simplicity I mean it strips away everything. It makes no assumptions. A hosted CaaS offering should distill content management down to its very essence, implied by the term itself: to manage content. Do nothing else. Take this chunk of JSON, free of any hint of style or presentation, and store it for me, making it available via a tool-agnostic API to my front-end channels to present as I see fit.
This pragmatic approach to content management can be implemented on-premises or on your own cloud-based servers using freely-available technology. I’ll talk more about that in another post. The nice thing about hosted CaaS is that you don’t have to assemble, test, scale, and maintain the solution yourself. Yes, you are giving up some amount of control, the degree to which varies across vendors, but many are willing and able to make that trade-off.
Business model
As with other Software-as-a-Service (SaaS) offerings, CaaS vendors charge a monthly subscription for their service. Some charge additional fees based on things such as number of content objects managed, number of content authors, and data volume. All of the market leaders I looked into provide a free-to-get-started plan to make it easy on developers in the early days of their projects.
Approach appeals to both startups and enterprises
The primary target market for CaaS vendors is clearly start-ups who are writing mobile and/or web apps that need some form of content management. Cost is usually a major factor for this segment, at least until the venture proves itself successful, but so is simplicity and efficiency. There’s no time for complex server installs, any sort of run-and-maintain burden, or pushing new app versions as content evolves. Hosted CaaS is a natural fit for these folks.
But this approach also make sense for enterprises, many of whom are still wrestling with their legacy content management vendor boat anchors (I’m looking at you, Interwoven). A hosted service that does nothing more than capture and share content chunks is a refreshing contrast to those bloated, over-priced WCM systems that require a huge staff to run and maintain yet still leave end-users frustrated.
Those systems haven’t changed much in nearly two decades and yet they remain firmly embedded in many companies where they are busy managing sites that may have been state of the art in 1999, but in a world where even the concept of a “page” is falling by the wayside, are now woefully outdated.
The content-as-a-service approach (API-first, native JSON, pragmatic, emphasis on reuse) aligns with how mobile apps and modern web sites are built and deployed as well as their content needs. This is true whether those apps are built by scrappy startups or huge enterprises.
Stay tuned for a CaaS round-up
So join me as I take a look at some of the players in the CaaS space. In the coming posts I’ll be looking at Prismic, Contentful, and Cloud CMS. If you have used any of these for your mobile or web project and you want to share your story with other ecmarchitect.com readers, do let me know.