

One of my clients came to me with a problem: Despite being a much-admired Fortune 500 company that leads its competitors in the travel industry in customer satisfaction and profitability, their web site, through which the vast majority of their revenues flow, was still mostly static. That by itself is not a huge problem, but they felt like they weren’t able to target content based on their customers’ needs and interests as well as they could with a more dynamic content engine.
It just so happened they were about to re-implement their site from mostly server-side to mostly client-side which is a huge undertaking. They figured that would be a pretty good time to add a dynamic content service to the mix, so they called me.
From Static to Dynamic
The diagram below depicts the high-level setup before the introduction of the content service.
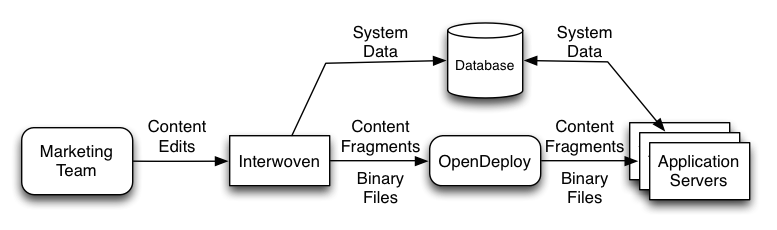 This is pretty standard for sites like this. The Marketing Team edits content in a Content Management System (CMS), which in this case is Interwoven. Through various processes, binary files (mostly images), system data (things like lists of destinations and hotels), and content fragments are published out of Interwoven to destinations accessible by the e-commerce application.
This is pretty standard for sites like this. The Marketing Team edits content in a Content Management System (CMS), which in this case is Interwoven. Through various processes, binary files (mostly images), system data (things like lists of destinations and hotels), and content fragments are published out of Interwoven to destinations accessible by the e-commerce application.
A content fragment is literally a piece of content. It might be a promotion of some sort. Or it could be some text that gets used as part of a banner. The challenge using this setup is that content fragments are static files that live on the file system. If you want to show a different fragment based on something you know about the user you have to generate every permutation you might want ahead-of-time, publish them all, then use logic in the application to decide which one to use.
One obvious way to address this is to publish content fragments in a relational database and then code the front-end app to query for the right content. That wasn’t appropriate here for a few reasons:
- The front-end is being migrated to a collection of Single Page Applications (SPA’s) written in JavaScript. It’s easier for those pages to call a RESTful API to get JSON back. Yes, you could still do that with a relational database and a service tier, but the client was looking for something a little more JSON-native.
- The structure of the content changes over time. We wanted to be able to accept any kind of content fragment the Marketing Team or SPA developers could think of and not have to worry about migrating database schemas.
- The anticipated style of queries needed to find appropriate content fragments was more like what you’d expect from a search engine and less like what you might put in a SQL query–we needed to be able to say, “Here is some context, now return the most appropriate set of content fragments for the situation,” and be able to use relevancy scoring to help determine what comes back.
So relational databases were ruled out in favor of document-oriented NoSQL repositories. Ultimately, Elasticsearch was selected because of its ease of clustering, high performance, unified REST API, availability of commercial support, and add-ons such as Shield, Marvel, and Watcher that make it easier to integrate with the rest of the enterprise.
Introduction of a Content Delivery Service
The first thing we did was stand up an Elasticsearch cluster, load some test data, and beat the heck out of it (see “Using JMeter to Test Elasticsearch“). Once we were satisfied it would be able to handle more than the expected load we moved on to the service.
The Content Delivery Service sits between Elasticsearch and the front-end applications. Its purpose is to abstract away Elasticsearch specifics and to protect the cluster by providing a simple, read-only REST API. It also enforces some light business logic such as making sure that only content that is currently effective according to its publication and expiration date is returned.
The diagram below shows the content infrastructure augmented with Elasticsearch and the content delivery service.
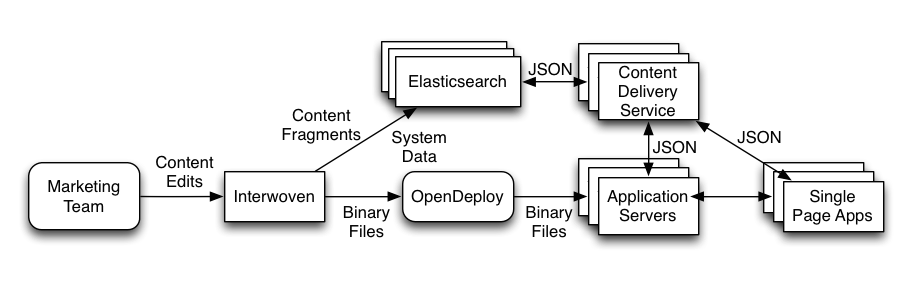 As seen in the diagram, Interwoven is still the source of record and the primary way Marketing manages their content. But now, content fragments and system data are published to Elasticsearch. The front-end Single Page Apps ask the Content Delivery Service for content based on some set of context. The content is returned as a collection of JSON objects. The SPAs then take those objects and format them as needed.
As seen in the diagram, Interwoven is still the source of record and the primary way Marketing manages their content. But now, content fragments and system data are published to Elasticsearch. The front-end Single Page Apps ask the Content Delivery Service for content based on some set of context. The content is returned as a collection of JSON objects. The SPAs then take those objects and format them as needed.
Content Objects are Pure Content
A key concept worth emphasizing is that a content object is pure content. It contains no markup. It might have some properties that describe how it is expected to be used, but it is completely lacking in implementation. This has several benefits:
- Content objects returned by the Content Delivery Service can be used across any and all channels (such as mobile) rather than being specific to a single channel (such as web).
- Within a given channel the same object can have many different presentations.
- Responsibilities are cleanly separated: The content service provides content. The front-end applications style and present the content for consumption.
This was a bit of a departure from how things used to be done. In the bad old days presentation was always getting mixed up with content which severely limits reuse.
Micro-services Provide Administrative Features
I mentioned earlier that the Content Delivery Service is read-only. And in my previous diagram I showed Interwoven talking directly to the Elasticsearch cluster. In reality, we don’t let anyone talk directly to the Elasticsearch cluster. Instead, all writes have to go through the Content Management Service. This ensures that we know exactly what is going into the cluster and who is putting it there.
The other role the Content Management Service plays is JSON validation. When new types of content objects are developed we use JSON Schema to codify the structure. When a person or system posts a content object to the Content Management Service, the service validates the object against its JSON Schema before storing it in Elasticsearch.
In addition to the Content Management Service we also implemented a Scheduled Job Service. As the name suggests, it is used to perform administrative tasks on a schedule. For instance, maybe content needs to be reindexed from one cluster to another in a lower environment. Or maybe content needs to be fetched from a third-party and written to the cluster. The Job Service is able to talk to either the Content Management Service or Elasticsearch directly, depending on the task it needs to execute.
All of the administrative services are independently deployed web applications that sit behind an API Gateway. The Gateway leverages the Netflix Zuul Proxy. It is responsible for authenticating against LDAP and creating a shared session in redis. It gives the content admin team a single URL to hit and isolates authentication logic in a single place.
The diagram below shows the fully-realized picture.
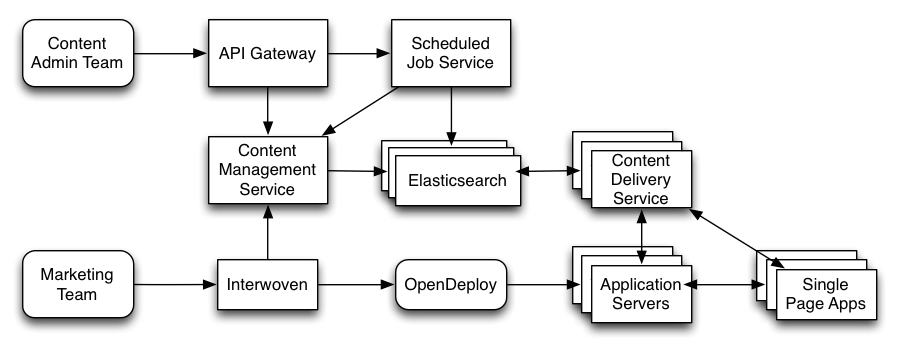 A few key components aren’t on the diagram. We use Shield to protect the Elasticsearch cluster. Shield also makes it easy to configure SSL for node-to-node communication and provides out-of-the-box LDAP integration. With Shield we can map LDAP groups to roles and then grant roles various privileges on our Elasticsearch cluster and its indices.
A few key components aren’t on the diagram. We use Shield to protect the Elasticsearch cluster. Shield also makes it easy to configure SSL for node-to-node communication and provides out-of-the-box LDAP integration. With Shield we can map LDAP groups to roles and then grant roles various privileges on our Elasticsearch cluster and its indices.
We use Watcher to monitor cluster health and job failures that may happen in the Scheduled Job Service. The client has their own enterprise alerting and monitoring solution, but Watcher gives the content management team a flexible, powerful tool for keeping track of things at a level that is probably more granular than what the enterprise ops team cares about.
Ready for the Future
With Elasticsearch and a few relatively small services on top of that, this travel giant now has what it needs to provide its customers with a more customized online experience. Content can be targeted to the users it is most appropriate for using any kind of context the Marketing team can come up with. As the front-end commerce app evolves, new types of content objects can be added easily and be served to the front-end with no schema or service changes required. And it’s all built on commercially-supported open source software.