
Drupal is a very popular open source Web Content Management system. One of its key characteristics is that it owns both the back-end repository where content is stored and the front-end where content is rendered. In CMS parlance this is typically called a “coupled” CMS because the front-end and the back-end are coupled together.
Historically, the coupled nature of Drupal was a benefit most of the time because it facilitated a fast time-to-market. In many cases, customers could just install Drupal, define their content types, install or develop a theme, and they had a web site up-and-running that made it easy for non-technical content editors to manage the content of that web site.
But as architectural styles have shifted to “API-first” and Single Page Applications (SPAs) written in client-side frameworks like Angular and React and with many clients finding themselves distributing content to multiple channels beyond web, having a CMS that wants to own the front-end becomes more of a burden than a benefit, hence the rise of the “headless” or “de-coupled” CMS. Multiple SaaS vendors have sprung up over the last few years, creating a Content-as-a-Service market which I’ve blogged about before.
Drupal has been able to expose its content and other operations via a RESTful API for quite a while. But in those early days it was not quite as simple as it could be. If you have a team, for example, that just wants to model some content types, give their editors a nice interface for managing instances of those types, and then write a front-end that fetches that content via JSON, you still had to know a fair amount about Drupal to get everything working.
Last summer, Acquia, a company that provides enterprise support for Drupal headed up by Drupal founder, Dries Buytaert, released a new distribution of Drupal called Reservoir that implements the “headless CMS” use case. Reservoir is Drupal, but most of the pieces that concern the front-end have been removed. Reservoir also ships with a JSON API module that exposes your content in a standard way.
I was curious to see how well this worked so I grabbed the Reservoir Docker image and fired it up.
The first thing I did was create a few content types. Article is a demo type provided out-of-the-box. I added Job Posting and Team Member, two types you’d find on just about any corporate web site.
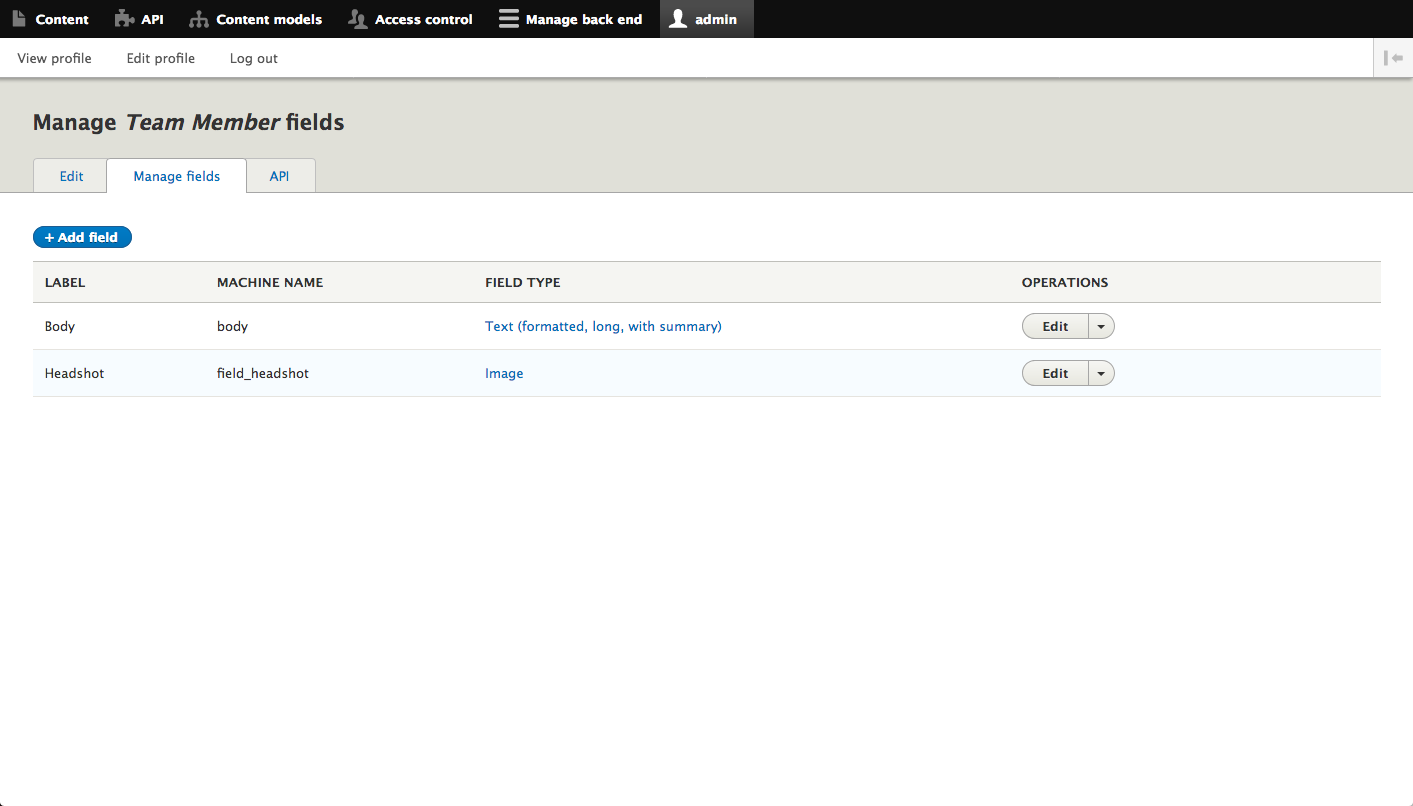 My Team Member type is simple. It has a Body field, which is HTML text, and a Headshot field, which is an image. My Job Posting type has a plain text Body field, a Date field for when the job was posted, and a Status field which has a constrained list of values (Open and Closed).
My Team Member type is simple. It has a Body field, which is HTML text, and a Headshot field, which is an image. My Job Posting type has a plain text Body field, a Date field for when the job was posted, and a Status field which has a constrained list of values (Open and Closed).
With my types in place I started creating content…
 Something that jumped out at me here was that there is no way to search, filter, or sort content. That’s not going to work very well as the number of content items grows. I can hear my Drupal friends saying, “There’s a module for that!”, but that seems like something that should be out-of-the-box.
Something that jumped out at me here was that there is no way to search, filter, or sort content. That’s not going to work very well as the number of content items grows. I can hear my Drupal friends saying, “There’s a module for that!”, but that seems like something that should be out-of-the-box.
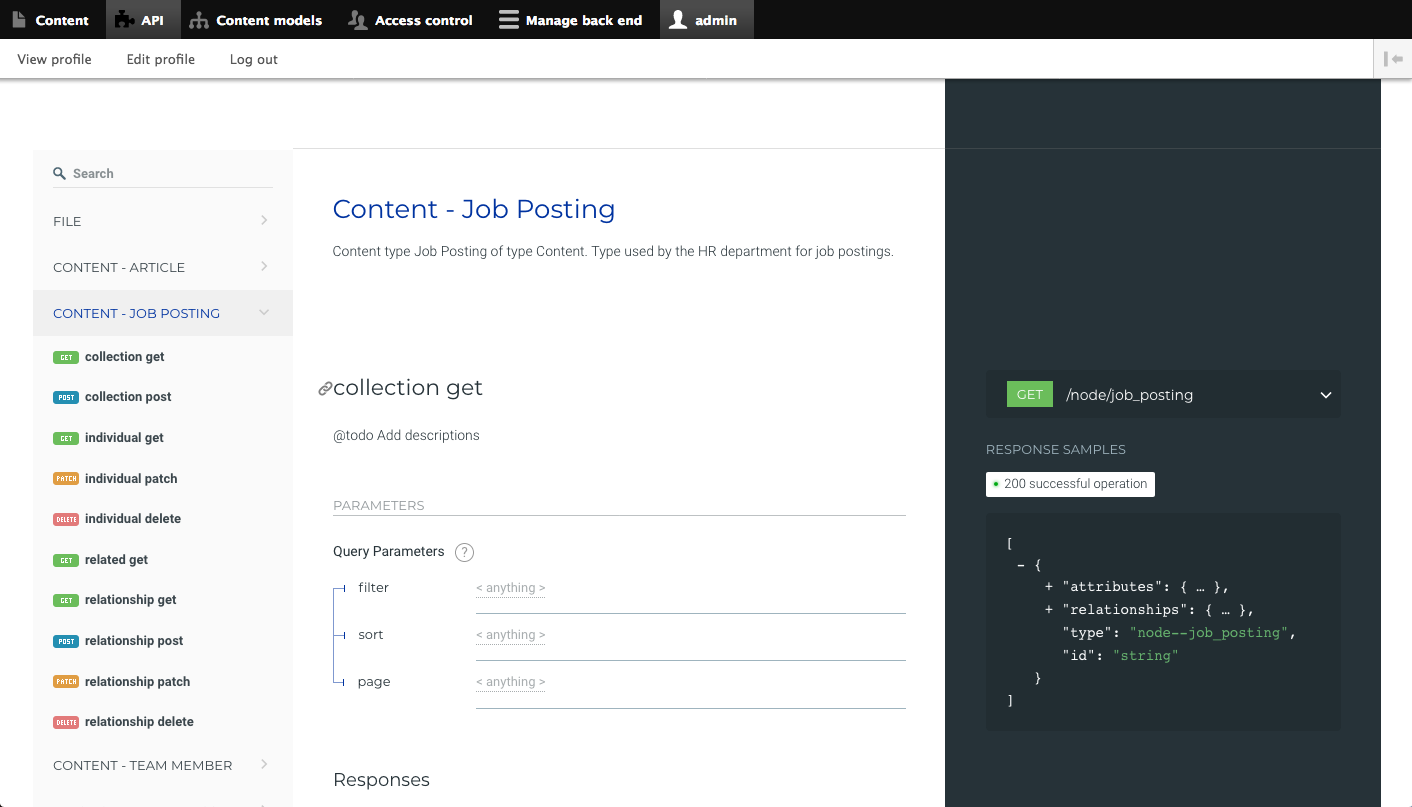
Next, I jumped over to the API tab and saw that there are RESTful endpoints for each of my content types that allow me to fetch a list of nodes of a given type, specific nodes, and the relationships a node has to other nodes in the repository. POST, PATCH, and DELETE methods are also supported, so this is not just a read-only API.
 Reservoir uses OAuth to secure the API, so to actually test it out, I grabbed the “Demo app” client UUID, then went into Postman and did a POST against the /oauth/token endpoint. That returned an access token and a refresh token. I grabbed the access token and stuck it in the authorization header for future requests.
Reservoir uses OAuth to secure the API, so to actually test it out, I grabbed the “Demo app” client UUID, then went into Postman and did a POST against the /oauth/token endpoint. That returned an access token and a refresh token. I grabbed the access token and stuck it in the authorization header for future requests.
Here’s an example response for a specific “team member” object.
My first observation is that the JSON is pretty verbose for such a simple object. If I were to use this today I’d probably write a Spring Boot app that simplifies the API responses further. As a front-end developer, I’d really prefer for the JSON that comes back to be much more succinct. The front-end may not need to know about the node’s revision history, for example.
Another reason I might want my front-end to call a simplified API layer rather than call Drupal directly is to aggregate multiple calls. For example, in the response above, you’ll notice that the team member’s headshot is returned as part of a relationship. You can’t get the URL to the headshot from the Team Member JSON.
If you follow the field_headshot “related” link, you’ll get the JSON object representing the headshot:
The related headshot JSON shown above has the actual URL to the headshot image. It’s not the end of the world to have to make two HTTP calls for every team member, but as a front-end developer, I’d prefer to get a team member object that has exactly what I need in a single response.
One of the things that might help improve this is support for GraphQL. Reservoir says it plans to support GraphQL, but in the version that ships on the Docker image, if you try to enable it, you get a message that it is still under development. There is a GraphQL Drupal module so I’m sure this is coming to Reservoir soon.
Many of my clients are predominantly Java shops–they are often reluctant to adopt technology that would require new additions to their toolchain, like PHP. And they don’t always have an interest in hiring or developing Drupal talent. Containers running highly-specialized Drupal distributions, like Reservoir, could eventually make both of these concerns less of an issue.
In addition to Acquia Reservoir, there is another de-coupled Drupal Distribution called Contenta, so if you like the idea of running headless Drupal, you might take a look at both and see which is a better fit.