Jeff Potts' personal blog about Alfresco, content management, BPM, search, and other stuff
Category: Content Management
Enterprise Content Management (ECM), Web Content Management (WCM), Document Management (DM). Whatever you call it this category covers market happenings and lessons learned.
Cloud CMS announced today that it has added support for CMIS. This is a nice addition for all sorts of reasons, but near the top from Cloud CMS’s perspective is that it makes it easier to migrate content from existing solutions into the Cloud CMS repository.
Back in November I did a series of reviews on content-as-a-service providers. One of my posts was on Cloud CMS. The post assumes you are looking for hosted content-as-a-service and shows how Cloud CMS compares to other cloud offerings.
What I think we’re going start seeing more and more, however, are people who might consider Cloud CMS as an alternative to traditional on-premises ECM vendors like Alfresco, Nuxeo, Documentum, and Microsoft. Although Cloud CMS was originally built to be a hosted, content-centric, back-end for mobile and web applications, it can just as easily function as your hosted intranet or document management repository.
With custom content models, event triggers, and custom workflows, you may find that the only difference between Cloud CMS and your current on-premises document repository is that you don’t have to worry about software or hardware installation and upgrades any longer.
Considering Cloud CMS as an alternative to traditional players may make sense when:
A 100% cloud-native solution is preferred. While Cloud CMS could be run on-premises it is certainly built to be hosted on your behalf. Plus, one of the benefits of letting Cloud CMS run, upgrade, and scale your repository is so you don’t have to.
Customization is important. Some of the traditional vendors have made cloud add-ons for their products, but they then lock down the content model and the user interface so that it cannot be customized. Cloud CMS offers the benefits of hassle-free operations while maintaining your ability to customize it to meet your exact requirements.
Budget is constrained. Clients who need enterprise-grade features and the peace of mind that a support contract brings but can’t justify the high cost of a traditional vendor’s enterprise license may find Cloud CMS to be a lower-cost alternative. Rather than licensing by the seat or the server, Cloud CMS cost is based on how and how much you use the system.
Clients who have very straightforward needs (simple file sync and share, for example) will probably choose something a little more utilitarian, like Google Drive, Box, Dropbox, or Amazon Zocalo. And, despite Cloud CMS recently having undergone an extensive security audit, I know some clients may still be reluctant to move to the cloud. Everyone else, though, should take a hard look at Cloud CMS.
I’ve recently updated the Alfresco Developer Series tutorials to work with version 2.0 of the Alfresco SDK and Alfresco 5.0.d (and Enterprise 5.0).
Note that the SDK is not backwards compatible. If you are running Alfresco 4.x you need to use the older version of the SDK. When you move to 5.0 you need to move to SDK 2.0. The steps to do that are roughly:
1. Merge your pom.xml with the one generated by the 2.0 archetype.
2. Copy/merge tomcat/context.xml.
3. Copy run.sh from a 2.0 project into yours. Only needed if you are using spring-loaded.
4. Copy/merge src/test/resources.
5. Copy/merge src/test/properties.
That part was easy for all of the tutorial projects. The time-consuming part was just updating the screenshots and a few of the steps. The code stayed the same across all projects.
If you are still on 4.x and you want to use the tutorials that are specific to the older version, just use the source tagged with “4.x” on github.
Angel said the talk was inspired by my blog post about an example add-on I created that allows you to define default folder structures that get populated in the document library when you create a new site (see share-site-space-templates on GitHub).
One of the other 9 enhancements Angel showed was how to hide the “Create Site” link. I’ve seen so many of my clients and people in the forums asking for this functionality, I decided to enhance it a little bit, put it in an AMP, and make it available on GitHub. You can download share-site-creators and try it out for yourself.
Here’s a little more about how it works…
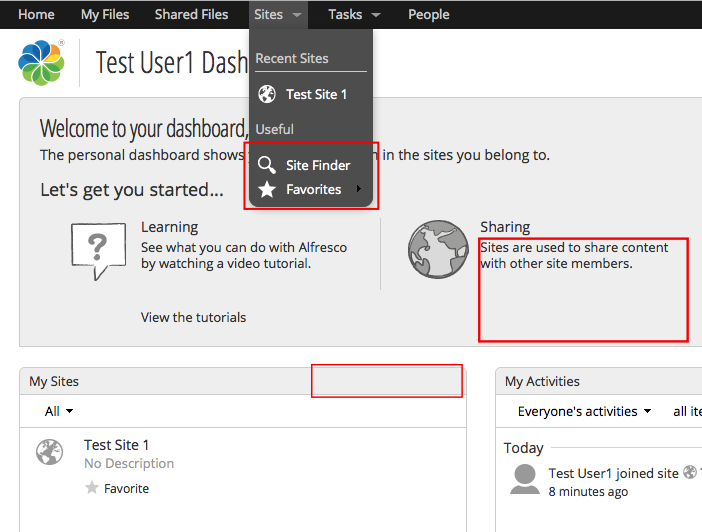
Instead of hiding the “Create Site” link from everyone but administrators, my add-on allows you to create a group that is used to determine who can create sites. The group, appropriately enough, is called “Site Creators”. If you aren’t in that group, you won’t see the “Create Site” link in any of these places:
The Sites menu
The “My Sites” Dashlet
The “Welcome” dashlet
Additionally, the add-on changes the underlying permissions at the repository tier so that if your teammates are hackers, they cannot circumvent the user interface and create their sites using other means.
The screenshot below (click to enlarge) shows what it looks like when you aren’t a member of the Site Creators group:
You might notice that the text of the “Sharing” column in the welcome dashlet also changes to be more applicable to someone who cannot create their own sites.
The new text is in a properties file. Currently I have only an English version, so if any of my multi-lingual friends want to translate the new string, that might be useful to others.
Just like my Share Site Space Templates add-on, this one is not mind-blowing. But it is useful, both in terms of functionality, and as an example of how to override Alfresco Share web scripts without copying-and-pasting tons of code.
I’ve tested this with Alfresco 4.2.f Community Edition. If you want to get it working with other versions, or you have other improvements, bring on the pull requests!
Things continue to be in flux at Alfresco with regards to how they manage their community. Today, Richard Esplin announced that he is stepping down as Head of Alfresco Community Relations to become a Product Manager for Alfresco Community Edition. In his blog post, Richard says that although his title changed a while back, his day-to-day job has still been mostly focused on the community, until now.
It sounds like rather than having a centralized team focused on managing the community, the various community touch points will be diffused throughout the organization.
Last month, Alfresco hired long-time community member, author, and former Ixxus employee, Martin Bergljung. I know through the grapevine there are more community hires on the way. These seem to be focused on “developer outreach” and “developer ecosystem” which is one aspect of community management.
I hope the “community is everyone’s job” approach does not lead to a “community is no one’s job” problem at Alfresco.
Related to Community Edition, Richard said, “I will be rethinking our approach to Alfresco Community Edition in order to make it a better product for its target audience”. My worry here is that there hasn’t always been agreement on what is the “target audience” for Alfresco Community Edition. In the past, Alfresco Software, Inc. has wanted the target audience to be developers who experiment and test out code that will ultimately become Enterprise Edition. The reality has been that many people want to run Community Edition in production–they want a high quality, free/libre open source software product that helps them solve document management problems.
Hopefully, Richard and the rest of the Alfresco team are aligned to the new reality of how Community Edition is being used.
It will definitely be interesting to see how these staffing shifts work out for the community.
Packt Publishing recently sent me a copy of Learning Alfresco Web Scripts by Ramesh Chauhan to review in exchange for my thoughts on the book which I’ll share with you now…
Web Scripts are an essential part of Alfresco. If you are extending or customizing the platform and you have time to learn only one thing about it, web scripts might very well be that thing. The reason is that they are key to so much else you might want to do such as integrating Alfresco with a third party system or customizing Alfresco Share, which is, at its core, comprised of web scripts.
Most technical books on Alfresco give some attention to web scripts, but this one dives into the details. After reading it, you’ll know how to do simple things with web scripts and you’ll have some idea of how to do more complex work beyond understanding the Model-View-Controller basics.
While the comprehensiveness is a good thing, I think it also presents a bit of a challenge which comes down to this: Who is this book for? If it is for beginners, it needs a lot more examples and could cut back on a lot of the technical detail. If it is for experts, point to existing sources for the basics and drill deeper on the interesting technical topics.
I did see a couple of bad practices in the book. First, in the chapter on Java-backed web scripts (Ch. 6) the author provides an example Spring configuration XML file that injects the lower-cased Alfresco beans into the web script class. This may sound like a trivial nitpick, but it’s actually a big no-no that I see repeatedly. If you have good reason for using the unsecured, internal-only, lower-cased beans, explain it. Otherwise, stick to the public, secured, upper-cased beans so that beginners don’t pick up a bad habit.
Similarly, there is a part that discusses where web script files can live in the Alfresco WAR. The author does point out that the extension directory is “preferred” but I don’t think this is worded strongly enough. Those other locations should have been left out entirely or maybe it could have said, “Place your files only in the extension directory. While these other locations may technically work, you should never use them.”
I was happy to see the chapter on the Maven SDK and the discussion of AMPs. And I think putting the Eclipse details later was a good idea, as one of the features of web scripts is that you don’t have to use Java or an IDE of any kind if you don’t want to. The book doesn’t cover Surf, Aikau, or Share customization in any detail, and I think that was also a good decision as those areas are too fluid at the moment and because the singular focus on web scripts is one of the book’s assets.
Overall, Learning Alfresco Web Scripts is a very thorough and comprehensive treatment of an important technical topic for Alfresco developers.
See if you can answer this question: What is the current stable release of Alfresco Community Edition?
Some of you probably blurted out “5.0”. But that’s not specific enough. Alfresco Community Edition releases have letters as part of the release name. Did I hear someone say “5.0.c”? That is certainly the latest version but is that the current stable release? I would argue that it’s not and that the correct answer to the question is actually “4.2.f”. That’s the newest version I would recommend to anyone wanting to run Community Edition in production.
The problem is that you can’t actually tell what is supposed to be the stable release by looking at the version labels like you can with virtually every other open source software project. Hindsight is actually the only tool we have. The reason 4.2.f is the latest stable release is because it was the last release in the 4.2 Community Edition code line. We won’t know which 5.0 release is the stable one until Alfresco stops creating 5.0 releases!
Really, 5.0.a, 5.0.b, and 5.0.c should be labeled 5.0-RC1, 5.0-RC2, and 5.0-RC3. I’m using RC for “Release Candidate” here because that’s basically what they are, but “snapshot” or “milestone” could also work. We just need something that indicates that, eventually, we’re going to see an end to the iterations and finally arrive on a stable release and that you should really wait to deploy to production until that stable release comes out.
If you look at 4.2, I think 4.2.e was the “final” release and then 4.2.f was a special release to address a serious security vulnerability. So 4.2, a, b, c, and d should have been “release candidates”, 4.2.e should have just been 4.2.0, and 4.2.f should have been 4.2.1. I wouldn’t expect the third digit, which normally signifies a “service pack” to be anything other than 0 for the vast majority of Community Edition releases. The 4.2.f release was an exception to the norm which is that Alfresco doesn’t provide service packs for CE.
The reason an easily identifiable release label is important is because today people in the community are going to the Alfresco download page and assuming that what they are downloading is a stable release. They are then installing and running that release in production. This leaves those people disappointed down the road when they find out they installed software with numerous known issues or partly-implemented features (I know those issues are often documented in the release notes and in Jira). The point is that downloaders, particularly newcomers, don’t have (and shouldn’t need) the insight that Alfresco releases don’t really settle down until the fourth iteration or so. That should be explicit.
The reason Alfresco doesn’t use “stable” to describe the release is partly commercial. The thinking is that doing so makes running the freely-available Community Edition in production seem less risky or even encouraged by the company that depends on revenue from the paid edition.
The other challenge is about process. I don’t think engineering always knows that a given Community Edition release is going to be the last one until after the fact.
Both of these could be addressed with a mindset change. Instead of “Let’s iterate on release X.0 until we’re ready to work on the next major release” the thinking ought to be, “Let’s drive toward a stable, production-ready X.0 release and once we think we have it, let’s call it that”.
I’ve heard chatter that Alfresco might, at some point, consider offering support for those running CE. Based on the number of SMB’s who have told me that Alfresco One is out-of-reach for them financially, there ought to be a strong demand for a low-priced subscription around Community Edition. If that happens, I assume both the mentality and the process around CE version labels will get cleaned up. But I hope we don’t have to wait.
The next vendor in my Content-as-a-Service (CaaS) round-up is Cloud CMS. If you missed my overview of the CaaS market, you might want to read that first.
Cloud CMS has been around since 2010. It was founded by Michael Uzquiano, formerly of Alfresco, Epicentric, and Vignette. This year they brought on a new CEO, Malcom Teasdale, who, prior to joining Cloud CMS, ran Rothbury Software, an Alfresco partner that was ultimately purchased by Ixxus. Malcom spent some time at Interwoven earlier in his career. So these two have a lot of content management experience and that’s evident in their product. (Disclosure: I’ve known Michael and Malcom for several years but I do not currently have a business relationship with Cloud CMS).
My CaaS overview described functionality you’ll find in all CaaS offerings. Similar to my posts on Prismic.io and Contentful, in this post on Cloud CMS I’ll focus on some select areas of the Cloud CMS offering:
User interface for content authors
Creating content types
Working with content via the API
Security
Pricing
Cloud CMS is an extensible platform with a long list of features. This is more than just a place to stick content and an API to get it back out–this is a full-featured CMS that happens to be running as SaaS in the cloud. But I’m primarily interested in it for its ability to act like a CaaS offering, which to me means a more pragmatic, stripped down approach to content management, so this review is going to ignore a lot of the Cloud CMS features that go beyond that. Perhaps I’ll come back to those in a future blog post.
User Interface for Content Authors
Before I describe the Cloud CMS user interface let me tell you a little about how Cloud CMS stores content. A Cloud CMS account has one or more repositories. How you use your repository is up to you–you might have one repository per project, for example.
Within a repository there are one or more branches. A branch works just like it does in source code control–it is a view of the repository. Each repository has a “master” branch, but you can have as many branches in a repository as you want. Branches can be areas where individuals work on content in isolation, or they can be for teams. Branches can never be deleted.
Within a branch are one or more changesets. Adding content to a branch (or making any change) takes place against a changeset–you’re never actually changing anything that was written previously.
And, finally, at the object level you have nodes. Everything in Cloud CMS is stored as a node. If you have a blog post, that’s a node. If your blog post points to an image, the image is also node. All nodes are typed. There are out-of-the-box types but you can also define your own. I’ll talk more about that in a bit.
Cloud CMS provides a web user interface that helps teams organize content creation built around the notion of projects. For the most part, your users see your repository through the lens of a project. They don’t have to understand the underlying structure of the Cloud CMS repository.
The first thing you see when logging in to Cloud CMS is a dashboard. From here you can manage your projects, tasks, members, and workflows. For my review I created a project called “My Cloud CMS Project”.
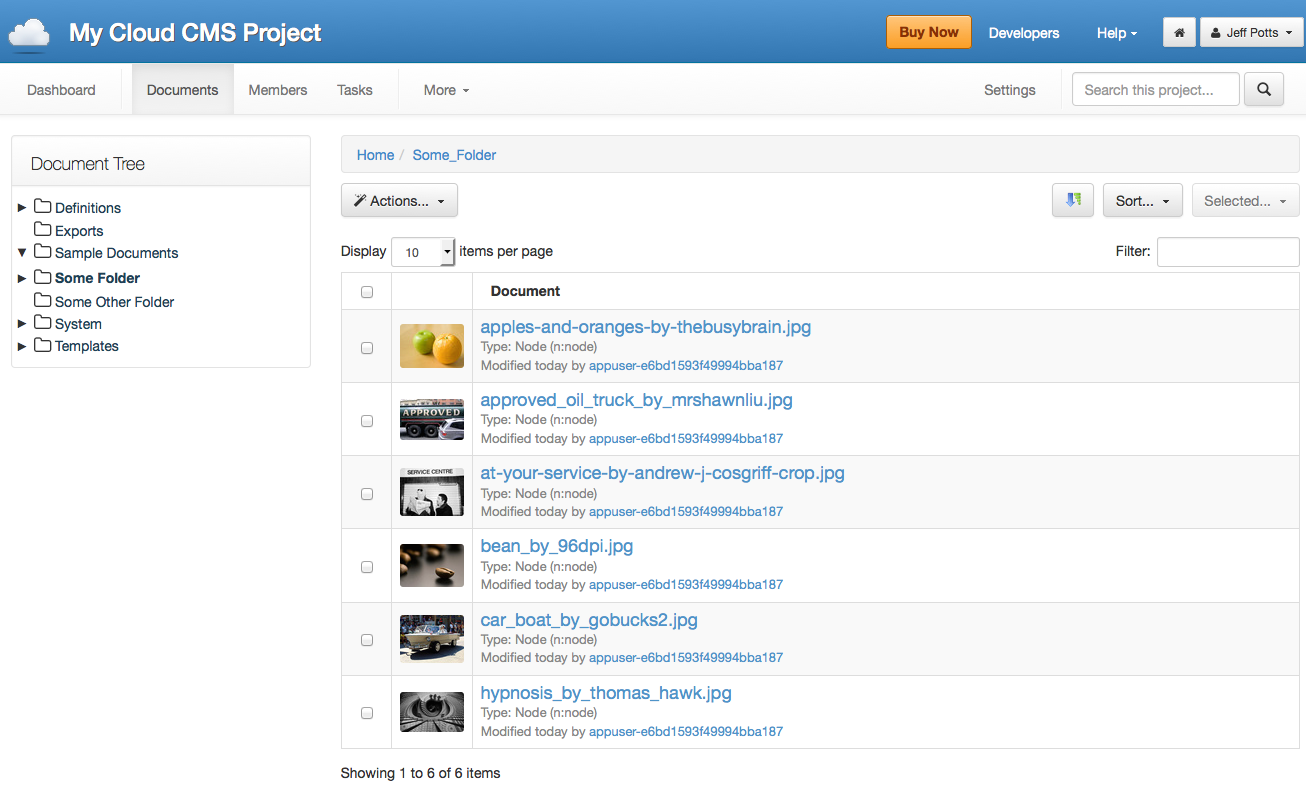
Drilling into the project displays the project’s dashboard. Clicking on Documents shows a hierarchical view of folders and documents. Multiple files can be dragged-and-dropped which triggers an upload to the folder. As you can see in the screenshot below, thumbnails are automatically created and displayed in the document list.
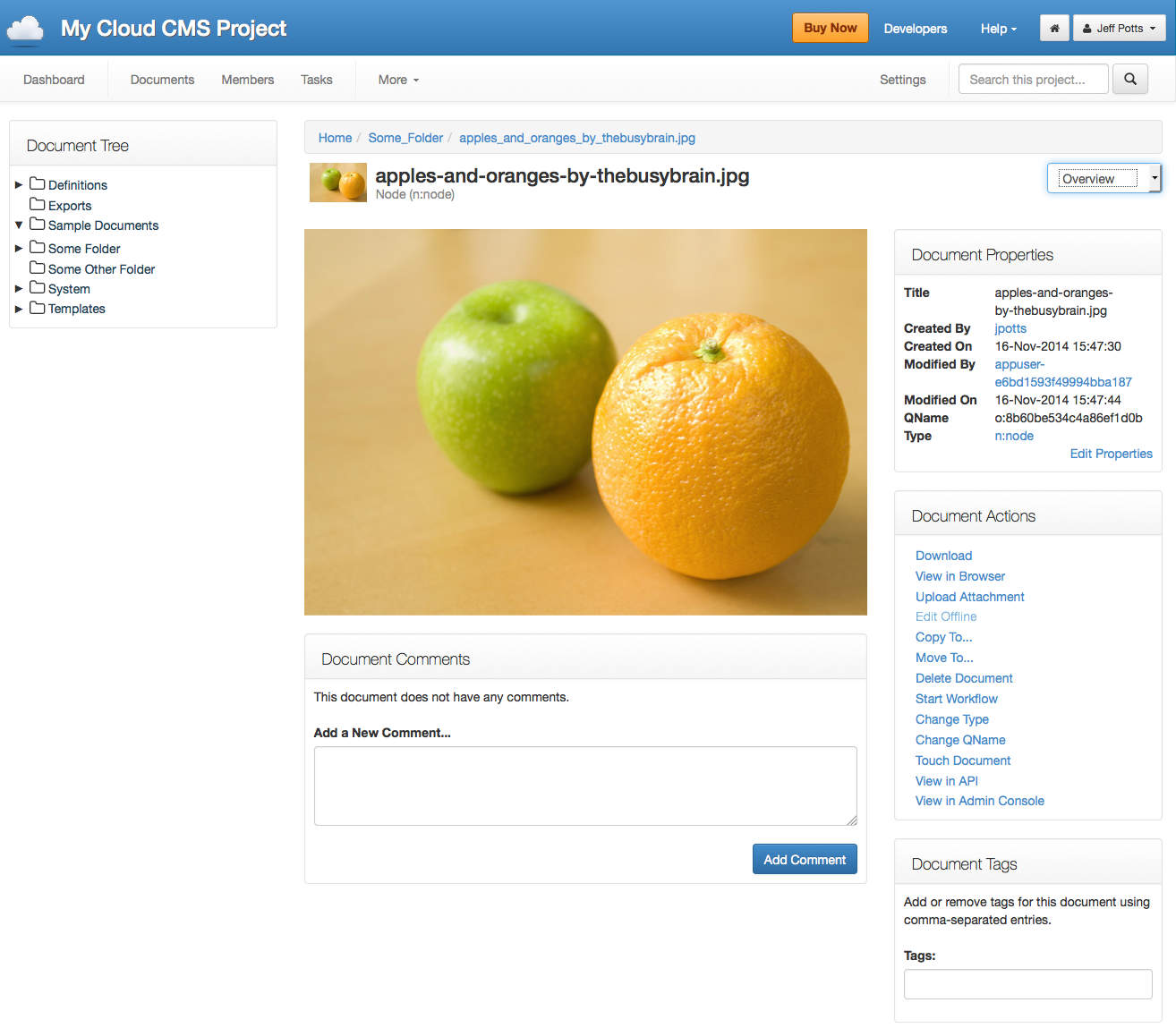
Clicking a specific document opens the details page for that object where users can edit the properties of the object, make comments, assign tags, start workflows, and perform a number of other actions.
So that’s how content authors manage content in Cloud CMS. Let’s take a look at how the content model is defined.
Creating Content Types
Content Type definitions are created using JSON Schema. You can define types using either the Cloud CMS UI by typing your JSON Schema into a web form, or by using the API. I really like the ability to define a content type simply by typing the JSON Schema that defines it. Of course, the trade-off is that you have to know how to define a type using JSON Schema. Fortunately, there is documentation that can help.
Content modeling in Cloud CMS is much more advanced than what I’ve seen in other CaaS offerings. Three examples of that are: hierarchical content models, aspect-orientedness, and role-based form definitions.
The first one, hierarchical content model, is easy to grasp: Your types can inherit from parent types. This can potentially save you time setting up your content model if your types lend themselves to being organized in a hierarchy.
The second one requires a little more explanation: aspect-orientedness. A content model is aspect-oriented when it has the ability to define bundles of properties that can be “attached” to objects, regardless an object’s underlying type. In Alfresco these are called “aspects”, in CMIS these are called “secondary types”, and in Cloud CMS these are called “features”.
For example, you might have a set of metadata that you want to track for anything that is “client-related” like the client’s name, industry, size, and primary contact. In Cloud CMS you define that set of metadata as the “client-related” feature, and then any object can become “client-related” just by adding the client-related feature–the bundle of properties having to do with a client–to the object.
The third advanced content model-related feature in Cloud CMS is role-based forms. When you create instances of a content type, Cloud CMS looks at the schema and generates a default form, similar to how other CaaS offerings work. What’s different is that Cloud CMS allows you to define multiple forms for the same content type. You can tie forms to specific roles so that different people see different authoring forms depending on their role. This is helpful when you have different types of people who need to edit the same content–you can use role-based forms to structure the form the way it makes the most sense for each type of user.
By the way, like content type definitions, form definition is also JSON-driven. Cloud CMS leverages the open source AlpacaJS forms engine into their product, which you might want to consider for your own projects, even if you don’t need Cloud CMS.
Working with Content via the API
Cloud CMS can host your application for you. This makes it nice for people who are looking for a one-stop shop for their content-centric mobile and web applications because you don’t need separate services for your content and your app. If you look back at the project dashboard screenshot I showed earlier you’ll see an example–I’ve created an application called “demo”.
What wasn’t obvious to me initially is that even if you are going to host your application elsewhere, you still need to create an application, and within that, a deployment. That’s where you’ll find the API keys needed to work with the API.
In addition to the API keys you’ll need to know your repository ID (which you can get from the Cloud CMS admin console). If you are going to fetch content from anything other than the master branch you also need the branch ID. Once you have that, querying for nodes is straightforward, as shown in this gist:
Under the covers, Cloud CMS is running MongoDB and Elasticsearch. So when you query for Nodes, you’re using Mongo. When you’re searching the full-text of your nodes you’re using Elasticsearch.
Everything in Cloud CMS is stored in JSON so creating content is as simple as calling createNode and passing in JSON for the property values:
Every object in Cloud CMS can have an ACL and child objects can inherit ACLs from their parents. There are out-of-the-box roles you can use in those ACLs, including: Connector, Consumer, Contributor, Editor, Collaborator, and Manager. Unfortunately, to set permissions on an object you have to switch from the project user interface to the administrative user interface. Still, this is the only vendor in the round-up offering object-level permissions.
Pricing
Cloud CMIS offers a free 14-day trial. After that you have to switch to one of four monthly plans:
Starter: $20/month. Limited to a single project and email support.
Platform: $200/month. Unlimited projects and email support.
Enterprise: $2400/month. Private cloud with an on-premises option
The ability to run the entire stack on-premises is an interesting option for those not ready for the cloud although I haven’t explored how practical that really is for Cloud CMS.
The usual caveats apply to pricing here. Like other CaaS offerings, Cloud CMS places limits on total storage space and data transfer so look at the details to make sure you understand what this will cost you each month.
Overall Impressions
Cloud CMS is a full-featured platform for content management. Where some startups focus on the minimum viable product, Cloud CMS has gone for a kitchen sink approach that approximates the functionality you might expect in more mature, on-premises ECM offerings. Cloud CMS can even be the platform that runs your application, if that’s what you need.
Content management professionals will appreciate the advanced content modeling and forms features, which is just one example of functionality that reflects the founders’ ECM industry heritage. The flip-side of that coin, however, is the complexity also reminiscent of those systems. The documentation and tutorial videos help but there is a learning curve here.
Cloud CMS can compete against CaaS players like Prismic.io and Contentful as well as established ECM vendors like Alfresco and Documentum. Compared to other CaaS players it has much richer functionality, but it is also more complicated to use. To compete against them successfully Cloud CMS may need to further streamline the UI so that users can harness that power without being overwhelmed by other features.
Compared to established vendors like Alfresco and Documentum, Cloud CMS offers a hosted system running in the cloud with a similar feature list while maintaining the ability to customize the platform. Customers looking to move to the cloud may find an easier migration to Cloud CMS than to one of the newer CaaS players. In this respect Cloud CMS also competes with other traditionally on-prem document management offerings now offered in the cloud like Hippo onDemand and Nuxeo Cloud.
With two ECM veterans at the helm and impressive functionality it will be interesting to watch Cloud CMS go after one or both of these markets.
It’s time for the next vendor in my Content-as-a-Service (CaaS) round-up. In this post I’ll be taking a look at Contentful. If you missed my overview of the emerging CaaS market you might want to take a look and then come back.
Contentful came out of beta to be generally available in May of 2014, so it is the youngest vendor of the three in my round-up. The company is based in Berlin and has a number of well-known clients including EA, Disney, Viacom, Asics, Nike, Playboy, and McAfee.
My CaaS overview described functionality you’ll find in all CaaS offerings. Similar to my post on Prismic.io, in this post on Contentful I’ll focus on the areas that typically differentiate one CaaS offering from another, namely:
User interface for content authors
Creating content types
Working with content via the API
Security
Pricing
Finally, I’ll wrap up with my overall impressions and takeaways.
User Interface
In Contentful you have one or more “spaces”. You can think of a space as a repository. It’s a collection of “entries”, which are instances of content types, and “assets”, which are file-based assets like images. In addition, each space has its own users, roles, and API keys.
When you log in to Contentful you’ll be sitting in one of your spaces (the first one in the list). The Contentful user interface is clean and quite minimal. It’s easy to get going quickly because you have a limited function set. You can define your content model, manage entries, manage assets, or manage your API keys and that’s about it.
Options for organizing lists of entries and assets are limited to filtering based on status (Published, Changed, Draft, Archived), content type (for entries), and file type (for assets). There is a saved search feature and saved searches can be organized into folders. But, there is no notion of hierarchical content storage.
This minimalistic approach to content management is what I characterized as a Good Thing in my Content-as-a-Service overview.
Content Types
Every content management system has a way to describe the data stored in the repository which is referred to as a “content model”. In Contentful, each space has its own content model which is simply a set of content type definitions. A content type is a set of typed properties. There are property types you’d expect, like text, date, number, decimal number as well as “pointer” types that reference other objects in the system, where those objects are either entries or file-based assets.
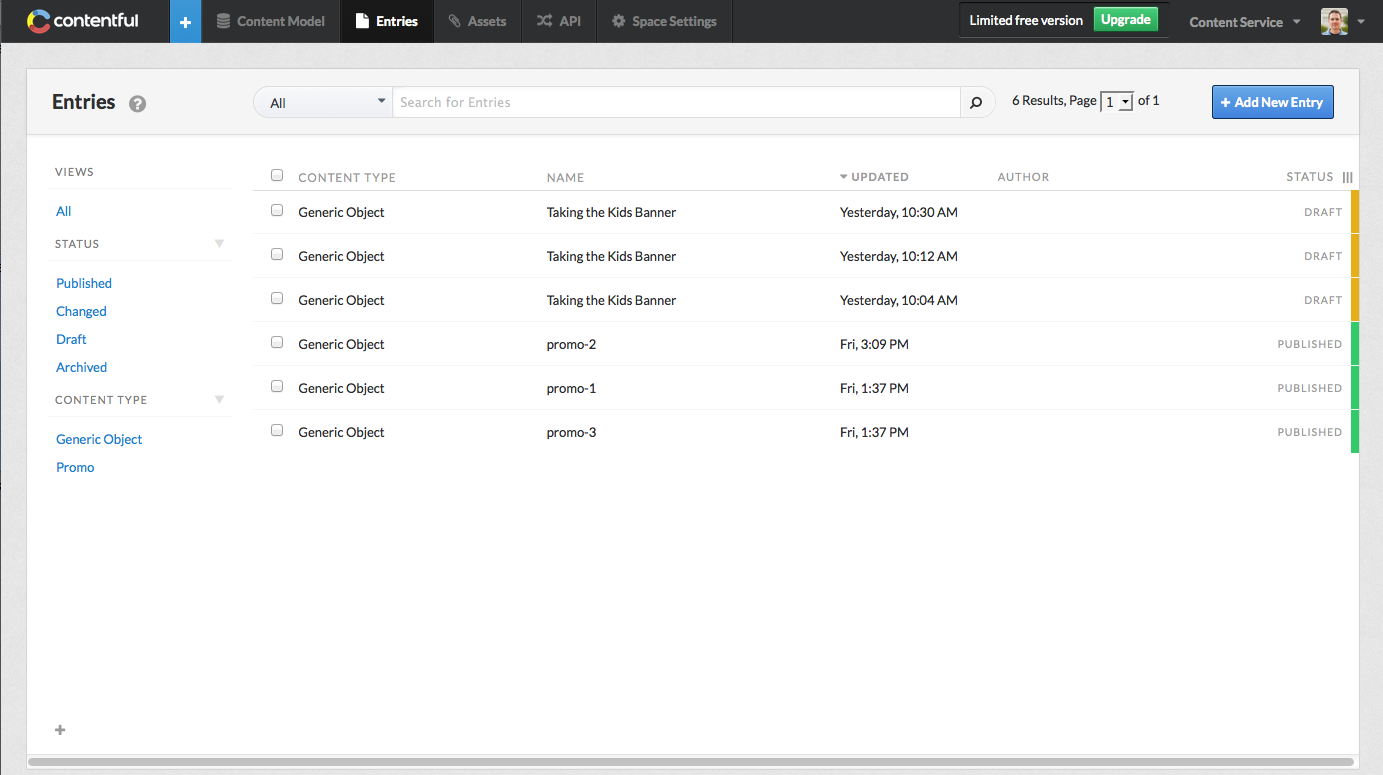
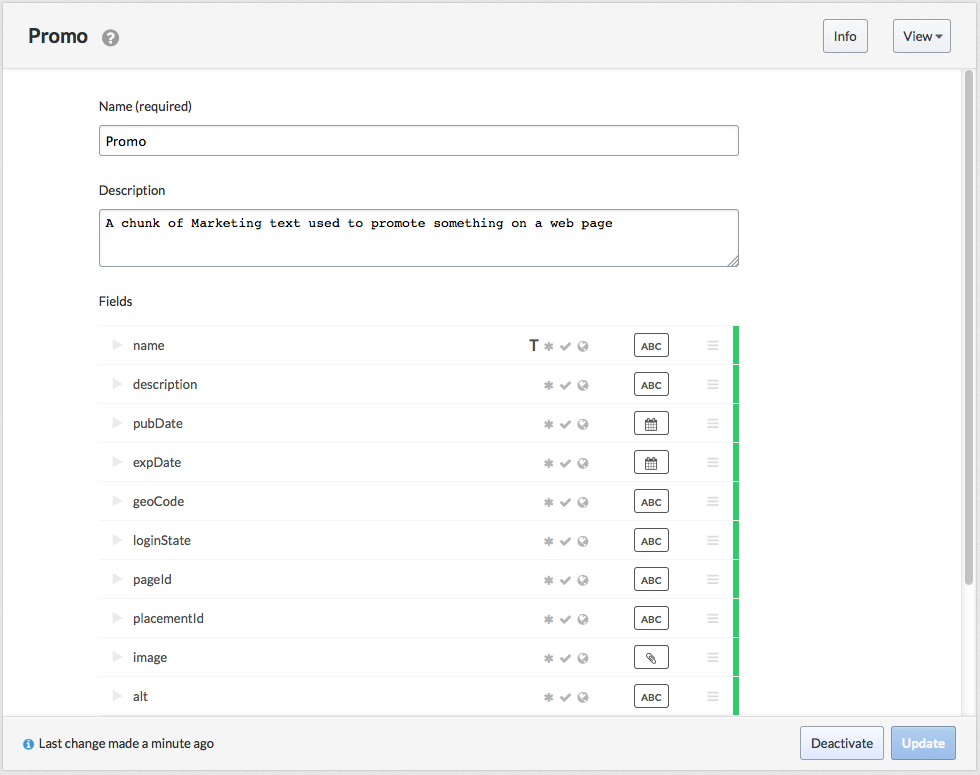
For example, the screenshot below shows a Promo content type I created. It has a name, a description, and a set of fields such as pubDate, geoCode, image, alt, etc. In the case of the image field, it points to a file-based asset.
Unfortunately, there is no support for cross-cutting concerns (aspects) so if you want to repeat property definitions across types you have to do that manually. For example, a type called “Cat Picture” and a type called “Dog Picture” might both have “height” and “width” properties. In Contentful, you have to repeat similar properties across type definitions.
On a related note, there is no way to clone or copy content types in the user interface. If you have two similar content types you have to re-do the property sets in each one or use the Contentful content management API to do this.
Managing your content model in the Contentful UI takes way too many clicks. I much prefer the approach other CaaS offerings take where you edit the content type definitions using JSON rather than the point-and-click approach. The nice thing with Contentful is that you can use the API for everything, including defining your content model–you don’t have to use the UI at all if you don’t want to.
One thing to watch out for: If you want to change a field on a content type (like maybe change the type of field) you have to deactivate the content type first. That’s not such a bad thing until you realize you cannot deactivate a content type without first getting rid of the instances of that content type. This could be a challenge once you go to production, so make sure you are happy with your content model before you get too far down the road.
Working with content via the API
Content can either be “published” or “draft”. The API keys you generate for a space can either be “production” or “preview”. The production URL and access key can only fetch published content. The preview URL and access key will see everything.
The Contentful Content Delivery API lets you fetch content by space which can be further filtered by query terms that will be AND’ed together. There was not an obvious way to OR query terms.
If you’d rather, Contenful offers client libraries in Java, JavaScript, Objective-C, Swift, and Ruby.
Here is a gist that fetches content using JavaScript:
If all you need to do is fetch content from Contentful, you’ll stick with their Content Delivery API. To create, update, or delete content, use the Content Management API.
Note that content is initially created in draft mode. You must publish the content if you want it to be retrievable via the “production” content delivery API.
I should mention that Contentful also offers a sync API, which is particularly useful for mobile applications.
Security
In Contentful, everyone belongs to one or more Organizations. Organization owners can create spaces and can invite users to a space. Users can be editors (edit all content) or developers (edit all content, manage API keys). Space admins can create new content types. The UI shows a “custom role” but this article says that custom roles will be implemented for the enterprise offering at some point in the future.
Contentful also makes it easy for agencies or consultants to administer an organization on their client’s behalf while the client remains the main contact for billing purposes.
Pricing
Contentful offers the following plans:
Free plan which is limited to 3 users, 3 spaces, and 1,000 objects
Plus plan for $99 per month which includes 5 users, 5 spaces, and 5,000 objects
Pro plan is $200 per month for up to 10 users, 10 spaces, and 10,000 objects.
Most of my clients would probably need the “Enterprise” plan which could cost anywhere between the low thousands to the tens of thousands of dollars per month depending on exactly what is needed.
Also, be aware that Contentful, like other CaaS vendors, places limits on additional things such as API requests, API bandwidth, and API keys. These and other details may change so take a look at the pricing page (click “Compare Plans” for the expanded details) to be sure.
Overall Impressions
Contentful is an extremely basic offering in terms of both the user interface and the capabilities of the underlying platform. But the simplicity of the offering is precisely what makes it so attractive. Developers will appreciate the “API-first” approach to content management, and without a lot of extraneous sub-systems getting in the way, they’ll be able to develop a solution quickly, and then let content authors manage the content with the easy-to-use interface. Contentful’s stripped down, pragmatic approach to content management is a category-defining building block you can use to create really cool content-centric solutions.
It won’t be long before we’ll be celebrating Alfresco’s tenth birthday. Sniff, sniff, they grow up so fast!
As part of that growth, it’s only natural that certain areas of the product will reach their end-of-life. Since its first release we’ve seen very little pruning of old or obsolete features, but that changes with the Alfresco Community Edition 5.0.b release.
Some of the things that have been dropped won’t surprise anyone. Some I consider regressions and may actually come back quickly, at least I hope they do. The surprises have been handled a little sloppily–Richard Esplin, the current head of community apologized for that earlier this week, essentially saying it was due to the rush to get 5.0.b out in time for Alfresco Summit.
You can read Richard’s post and the release notes for the full list of feature removals. In this post I’ll call out the major items you will no longer find in Alfresco Community Edition as of 5.0.b.
Alfresco Explorer
If you’ve paid any attention to my blog or just about anyone else who speaks or writes about Alfresco you already knew to avoid the original JSF-based web client called “Alfresco Explorer”. It’s the original web client accessible at /alfresco.
Alfresco has been saying Explorer was going away for a long time and they’ve finally done it. If you fire up Alfresco 5.0.b Community Edition and go to /alfresco you’ll find our old friend is no more. Good night, sweet prince!
All of my clients have been focused on Alfresco Share for years so if the impact of the change was simply that you couldn’t log in to that old client any longer it wouldn’t be a big deal, but there has been some collateral damage, which brings us to the next section…
Workflow Console, Tenant Console, or Basically Any Console
Unfortunately, some vital consoles leveraged the same JSF code base as Alfresco Explorer. When that went, these consoles went as well. The old saying about babies and bathwater comes to mind.
The removal of the workflow console is particularly irksome. It’s critical to anyone doing anything with either Activiti or jBPM in Community Edition. In my opinion, this is the most important console of the bunch.
The data dictionary console is also gone, which is used to enable or disable hot-deployed content models. If you only use content models deployed as part of the WAR this won’t affect you.
The tenant console is also gone. This obviously won’t affect you unless you are using the multi-tenancy feature.
The AVM console is also gone, but then again, so is the AVM as I’ll touch on briefly next.
The frustrating thing about these missing consoles is that they aren’t planned to make a return until 5.1, according to Richard. That makes 5.0 Community Edition harder to use than it needs to be. It’s possible that Alfresco will make the console framework available so that the community can help get these back in place quickly.
The AVM
The AVM is the ill-fated Web Content Management offering that Alfresco told you was reaching its End-of-Life back in February of 2012 so, again, you should not be surprised about this one. All but a handful of people have found other WCM solutions.
Lucene
This one sparked a WTF moment on Twitter earlier in the month when I was shocked to realize that 5.0.b Community Edition required Solr to be fully functional. Without it, you can’t do a people search, for example. Actually, you can’t do a full-text search either. So in my book, this makes Solr required to run.
Prior to this change you could choose either Solr or Lucene. I often used Lucene locally because it was one less WAR to deal with and it was the default when doing a manual WAR install. Some people preferred Lucene’s in-transaction indexing over Solr’s asynchronous indexing and eventual consistency.
I understand that Solr is the way forward for Alfresco. It just felt like this one was a bit rushed. I don’t remember any public communication saying that Lucene would no longer be an option in 5.0. The Alfresco Product Support Status page doesn’t list it either. Richard’s post says, “When we added Solr to Alfresco 4, we deprecated Lucene.” That may be true, I’m just not sure Alfresco told anyone, although it is possible I missed it.
SDK, API, & Publishing Features
The release notes for 5.0.b includes a “Feature Removals” section. Noteworthy entries include:
The old Java SDK has now been replaced with the Maven-based SDK in Github. This has been a long time coming.
The CMIS API endpoints from 3.x and 4.0 have been removed (use the 4.2 URLs). People are constantly using the wrong CMIS service URL for their version. Maybe this will help that.
These are all positive changes and I suspect will help Alfresco a lot on the engineering and support side.
Future Removals
The release notes also include a note that NFS and jBPM are now officially deprecated. I’ve been expecting the jBPM removal for a while now. If you haven’t started moving everything to Activiti process definitions you should definitely do so now.
Getting the old stuff out of the distribution is great–I’m glad to see it. I hope that going forward Alfresco can do a better job communicating openly in a timely manner about major changes like dropping Lucene. It sounds like Richard is going to take that on as part of his new role in Product Management, which is a very good thing.
Today I’m going to take a brief look at Prismic.io. Prismic.io is one of three commercial Content-as-a-Service (CaaS) vendors I’m reviewing as part of my CaaS round-up. If you missed my overview of the emerging CaaS market you might want to take a look and then come back.
Prismic.io was founded by Sadek Drobi, one of the co-creators of the Play framework, and Guillaume Bort, one of the Play lead developers. It launched in early October, 2013.
My overview talked about the kind of functionality you’ll find in all CaaS offerings. In this post on Prismic.io I’ll focus on the areas that typically differentiate one CaaS offering from another, namely:
User interface for content authors
Creating content types
Working with content via the API
Security
Pricing
Finally, I’ll wrap up with my overall impressions and takeaways.
User Interface: Let me show you to your room
Your Prismic.io account starts out with a sample repository called Les Bonnes Choses (The Good Stuff) and some sample content within that. The repository and sample content powers a sample web app for a fictitious pastry shop.
When you first log in to Prismic.io a dashboard lists the Les Bonnes Choses repository and any other repositories you’ve created. A quick side-note on repositories: When creating a new repository I was forced to pick a name no one else had taken. The repository name is used as a sub-domain under prismic.io, so I see why it has to be unique, but this seems like an odd choice for a service I’m sure the founders are hoping will grow wildly.
Anyway, clicking on a specific repository takes you into that repository’s “writing room”, which is the primary interface for not only authoring content but also configuring your repository’s various settings.
The writing room UI is certainly the most polished of any of the CaaS vendors I reviewed. While it looks great, I feel like the fly-in/fly-out animation is a bit over-used and many of the icons are un-labeled. The UI also uses colors to indicate status, but the meaning is not obvious initially.
The overall organizational model is activity-centric rather than asset-centric. If you’ve got a team of people pushing out content in a rather flat hierarchy this will probably work well. If you like a more traditional list-of-assets-in-a-nested-folder hierarchy you’ll have to adjust. The “Live Now”, “Your Documents”, and “Favorites” help filter the list of content.
Releases provide snapshot capability
A helpful concept in Prismic.io is the “content release”. This gives you the ability to plan releases ahead-of-time. When your content authors write content they can publish it to a release. When the release is published, all content associated with that release goes live. You can control who can access to-be-published content in the API settings.
Creating content types
In Prismic.io, content types are called “Document Masks”. Document masks are defined via the Prismic.io UI by writing JSON that describes the mask. For example, here is a snippet from the Blog Post document mask:
Notice that there is an object called “Blog Post” and an object called “Metadata”. These are rendered as tabs in the writing room UI. You can segment your document mask definitions however you see fit. Within the top-level object there are one or more fragments, each of which has a name, like “author”, a fieldset, a type, and a config.
Looking at the “author” config you can see that it is possible to add references to other documents in the repository. In this case the association is between the blog post and an author object. Elsewhere in the blog post example are similar links to “related posts” and “related products”.
I like that the content type definitions are expressed as JSON. It’s a lot easier to work with definitions in this way than with a UI-driven approach, especially when the content type definition language is fairly rich, as it is here.
Another nice feature of the document mask editor is the ability to quickly preview what the form will look like in writing room.
Collections and Bookmarks
Document masks define the type of documents your content authors can create. Prismic.io also gives you the ability to define collections and bookmarks.
You can think of a collection as a saved search. A collection defines a set of filters (document masks and/or tags). Content authors can then navigate to content by clicking collection names in the writing room. In fact, aside from the filters I mentioned earlier, collections are the only way to organize content.
Your front-end can use the API to get the documents matching a collection by specifying the collection name rather than building the query from scratch. I’ll show you an example of that in a minute.
A bookmark is a collection for a single document. It is kind of like an alias. Suppose you are building an app that needs to promote a “deal of the week”. The deal might change from time-to-time. One way to implement this would be to create a bookmark named “dealOfTheWeek” and point it to a document for this week’s deal. The front-end app can always ask for the same bookmark, but the object it points to can change as needed.
Fetching Content via the API
There are multiple client-side libraries you can use to work with content in Prismic.io including JavaScript, Python, Java, Ruby, .NET, PHP, and Scala. You can get more info from the Prismic.io developer page.
Here’s an example showing how to get the documents in a collection named “blogPosts”:
In the bookmark example you can see that once the document ID is fetched from the bookmark I constructed a query against the “everything” collection using the ID. This barely scratches the surface of what’s available in the query language–check out the developer docs to learn more.
One extremely disappointing thing about the Prismic.io API is that it is read-only. Yes, you read that right. Prismic.io is a content service that only lets you read content via the API, not create it.
The lack of a write API means that if you have existing content that you want to move to Prismic.io, there’s no way to do that short of hiring a bunch of temps and re-keying it into the system. Potentially worse, if your content originates from some other system and you want to use Prismic.io for delivery, there’s no way to do that either. And of course if you have user-generated content you need to persist from the front-end, you’ll have to write to some other service.
I suspect that a year from now we will all agree that a write API is table stakes for a viable CaaS offering and Prismic.io either will have fixed it or they will have relegated themselves to a microscopic corner of the market focused on tiny, greenfield, content silo projects. We shall see!
Security
By default, the API requires an OAuth token. Per repository, you can change that. For example, you might make it so that the API can fetch content from the “master” release without a key, but fetching content from future releases requires a token. Or, you can make access completely open.
Pricing
With Prismic.io, development is free. You don’t pay until you go to production. There are three paid plans available: Simple gives you all of the featues, but is limited to three users for $7/month. Team gives you unlimited users for $40/month. Enterprise gives you an SLA and a private cluster but you’ve got to negotiate pricing.
Something that’s pretty cool for all of my open source friends is that if you make your content available under the Creative Commons 4.0 license, you can use a Simple plan for free.
These plans, pricing, and details may change, so take a look at the official pricing page.
Overall impressions
The lack of a write API for programmatic content creation makes Prismic.io a non-starter for anyone having anything more than the most modest requirements, particularly in cases where there is a large volume of pre-existing content or when other systems need to write into the content store.
If you have the luxury of starting with zero content and all of your content will be created by humans using the snazzy Prismic.io user interface, then it is worth considering.
Prismic.io certainly has the most helpful developer on-ramp of any of the solutions I looked at with lots of client libraries, good examples, decent documentation, and useful starter apps. And I also liked their “free while you are developing” model, which makes it easy for teams to get started building their real solution, rather than a scaled-down PoC.
If Prismic.io puts a write API in place they’ll be a strong CaaS contender.