Well, Justin, high school graduation is behind you, you’ve landed in San Jose, and tomorrow morning you’ll wake up in Mountain View to start your internship at Mozilla, your first real world, paying job that’s aligned with your career goals.
I am so proud of you for all that you’ve accomplished and I know you’re going to have a great summer. But I have this fatherly need to impart wisdom, and I couldn’t fit it all in at the airport drop-off this morning, so I’m putting it here and linking to it from Twitter where you’ll be more likely to read and absorb it…
1. Don’t stand around with your hands in your pockets.
In every business there is always work that needs to be done. Don’t literally or figuratively just stand there doing nothing. Jump in and contribute value.
2. There is something to learn in even seemingly crappy tasks.
Every project has less desirable tasks and someone’s got to do them. If that’s you, don’t get discouraged. Take the grunt tasks on with a smile, knock them out quickly with quality, and find a lesson those tasks offer. Learning something new makes any task worth it.
3. Learn something new every day.
Speaking of learning, try to learn something new, no matter how small, every day. Actually, this applies to the rest of your life, not just your work life. If you get to the end of the day and you can’t answer, “What did I learn today?” that’s a day wasted, and it’s on you to fix.
4. Be confident, but practice gratitude and humility.
You’ve contributed countless hours to Mozilla, you’ve honed your skills, and you’ve successfully navigated the vetting process. So be confident that you’ve earned the right to be there. But something to reflect on daily, maybe as you walk to work in that gorgeous northern California weather, is how fortunate you are to have this day, this opportunity, in this place, and what you will do now to capitalize on it.
5. Have fun. Live in the moment.
This summer is going to fly by. And you’ll have your whole life to work. So my biggest piece of advice is to have fun, try new things, and to savor every single moment. Seriously, it sounds easy but it is so hard to do. When you are with your friends, standing on that hill overlooking the Golden Gate Bridge, I hope you’ll pause, take a few breaths, and really just soak it up.
So there you go. Hopefully, I’ve been working these in to your brain over the last 18 years so maybe it didn’t need to be said, but thanks for letting me say it anyway.
Oh damn, I almost forgot: Dress in layers, Facetime your Mom, Snapchat your sister, keep your wallet in your front pocket on public transit, if you’re on-time you’re late, be discreet and watchful at ATMs, always wear a helmet, be a thoughtful and considerate roommate, and stay away from the Tenderloin.
My friend and colleague, Peter Löfgren, recently wrote a blog post on what he sees as the two possible strategies Alfresco could pursue. He describes the two approaches as follows:
Vertical: You try to get as many as possible Community installs be converted to paying Enterprise customers. Convert from the bottom and up if you so like.
Horizontal: You try to get as many as possible to run Alfresco, even if they run the free Community version. A fair share will always want commercial support to have a professional backing. A broad approach, where you get market presence and self-sustained marketing.
Peter argues that, to date, Alfresco has used a vertical approach, which is really about pushing Enterprise Edition and begrudgingly acknowledging that Community Edition is an acceptable alternative, only when the client can’t currently justify the expense of an Enterprise Edition license.
Peter observes that the vertical approach pits Alfresco Enterprise Edition squarely against Community Edition making it very tempting for Alfresco sales people to badmouth Community Edition, because they often see it as cannibalizing their revenue. I actually don’t see this happening much anymore–sales people know that denigrating Community Edition is counter-productive because customers are savvy enough to know it is the same software and a good portion of the sales team understands the bigger picture.
Before I go any further, I should refer you to a blog post I wrote about a year ago called, “The plain truth about Alfresco’s open source ethos“. In it, I argue that Alfresco’s marketing strategy isn’t the community’s concern, and that the company is basically a “normal” software company that won’t ever be the dogmatic open source company many of us wish it was.
But Peter brought it up and I like discussing such things, so I’ll ignore my own advice and provide my take on why I think Alfresco will continue to ignore the horizontal strategy and will continue to basically act like any other traditional software company…
Here’s my take
First, let’s compare Alfresco with another commercial open source company, Elastic. Elastic is the company behind the popular search engine Elasticsearch as well as a variety of related big data and analytics tools such as Logstash, Kibana, and Beats. Like Alfresco, Elastic makes money from support, and their incentive to get people to pay for support is to offer a set of products they make available only to paying customers. Unlike Alfresco, Elastic ships a single distribution of their products. For a given release of Elasticsearch, for example, there is no difference between what a paying and non-paying customer downloads and runs. It’s just that if you want some additional value-add on top of what’s freely-available, you have to pay.
So this is an example of a horizontal pursuit as Peter describes it. The reason it is working for Elastic, though, is that their offerings are much more horizontal than Alfresco’s. Elasticsearch is more popular and more widely used in all kinds of use cases. Their download stats are impressive and increasing steadily.
Alfresco, on the other hand, is niche software. It is quite narrowly focused on document management. Yes, there are a lot of use cases within that, but it isn’t something that you see embedded in all sorts of applications like you would a database, a workflow engine, or a search engine. I suspect download stats are flat or maybe even decreasing, although this is a bit of an apples/oranges comparison as the two products are in different phases of maturity and adoption.
The other issue is one of leadership. Elastic’s CEO, Steve Schuurman, exudes open source. He was a co-founder of SpringSource, for example. Both he and Shay Bannon, the creator of Elasticsearch, have said repeatedly that Elastic will always be open source and that they’ll never have an Enterprise-only distribution of their core software. That’s the kind of leadership I expect from a commercial open source company.
Contrast that with the current leadership at Alfresco. When former CEO John Powell announced his retirement, the board could have chosen someone with open source credibility like Elastic’s Steve Schuurman. Instead, they went with Doug Dennerline. He and his lieutenants have next to zero open source credibility or experience. It is clear they were brought on solely to take the company public. For them, open source is not a driving part of their worldview. Instead, their focus is simply to build a software company and take it public, employing whatever strategy gives them and their shareholders the biggest revenue numbers year-after-year. (I don’t mean to paint this in an overly-negative light–it is what it is. I’m just trying to point out the stark contrast in motivation and philosophy between the two leadership teams).
Unfortunately, a horizontal strategy does not necessarily equate to those kind of numbers. With Red Hat as the notable exception, it is hard to find a commercial open source company with financials that Doug, the board, and investors are looking for.
Do the math. Let’s assume there are 50,000 installs of Alfresco Community Edition. I have no reason to believe that is accurate–this is just an exercise. What kind of conversion rate would you expect? You’ll probably guess too high, forgetting that Alfresco is now very expensive, even for modest installations, and that the company is still working to add more differentiation in its paid offering compared to the free product. Let’s use 2%. So that’s 1,000 paying customers, which is roughly the number John Newton disclosed publicly in a keynote several years ago. It’s probably higher now, but remember that there is attrition we haven’t accounted for and those customers have to be earned year after year.
Now, what do you think the average sales price of Alfresco is across all of their paying customers? Again, just spit-balling, let’s say it is $100k annually. Multiply that times 1,000 and that’s “only” a company with $100 million in annual revenue. If you’re looking for a $1 billion IPO, that’s not enough. (If EMC sells Documentum to someone for 10x revenue I’ll have to update this post, but I think I’m pretty safe).
In a horizontal strategy, those are your levers: Total installs, conversion rate, attrition, average sales price. For example, using the horizontal approach, to increase revenue from $100 million to $300 million you would have to triple the number of Community Edition installs from 50,000 to 150,000. Alternatively, you could keep CE installs steady at 50,000 and instead triple your conversion rate from 2% to 6%. Which seems easier?
My bet is that rather than increasing total Community Edition installs, Alfresco will find it easier to increase the conversion rate by increasing differentiation between the two products, cutting attrition by implementing “customer success programs” and consulting, and continuing to put upward pressure on the average sales price by charging more for the core product and finding new paid add-ons to sell.
The horizontal approach Peter advocates may be the one we all wish would work, but I think that ship has sailed.
I started blogging back in 2001, stopped, then started again in 2002. Those early posts were all over the map, topic-wise, and they were often very short blurbs on really random stuff. I was scratching a creative itch–I just wanted to write and I didn’t care too much about what. It wasn’t until 2005, when Alfresco was first released, that I started to narrow my focus and really find my voice.
I’m often uncomfortable singing my own praises, but over the last ten plus years I’ve heard from so many of you–in person, via email, in comments, and forums–that what I’ve written has made a significant difference in your professional lives. For some it simply helped you fix an annoying issue. For others it saved a project. And multiple people have credited it with giving them the confidence to make a career change into jobs where they could follow their passion. Regardless of the significance, each of those stories makes me very happy.
I started this blog selfishly, as a way of keeping track of what I was learning about open source ECM, search, and workflow, and documenting that for my teammates and clients. I figured why not make the knowledge available to the public–maybe a few others outside of those circles would derive benefit from it.
What I didn’t know at the time was that my blog would eventually:
Lead to a new job at what was then an open source-focused consulting firm
Result in a book deal and then another book deal
Launch a temporary career experiment in community leadership in a C-level position
Become a go-to reference for half a million technologists and business users from all over the world (true, that’s not “unique users”, but still).
I realize I’m not solving world peace. And this is one of many tech blogs focused on ECM and related technologies. But it’s kind of cool to see what ten years of picking a subject and writing about it when the mood strikes me ultimately turned into. So I wanted to take a minute to kind of appreciate that.
I also wanted to say thanks to you. To those reading this now, to anyone that’s ever left a comment, to anyone that’s ever stopped me and told me your story: Seriously, thank you. Your continued support means a lot.
What’s next for ecmarchitect.com? No idea. I’m sure you’ve noticed that I’ve been trying to mix it up a bit, to be less Alfresco-focused. That’s reflected in my client work, so it’s natural it comes through here as well. Ultimately, I suppose I’ll continue to write about what interests me, and hopefully you’ll continue to find it interesting and helpful as well.
If you have ideas on topics you think might be good to explore in this space, let me know in the comments.
This post covers the significant new features of Alfresco Community Edition 5.1. I’ve also published a YouTube video that demos the new features.
New Release Names
Alfresco Community Edition 5.1, which you may see referenced as “201602-GA”, has been released. This is the first GA release of Alfresco Community Edition using the new release naming nomenclature. Let’s talk about that first, then I’ll give you the highlights of what’s new.
In the past, Community Edition releases were assigned letters. For example, the last release in the 5.0 line was 5.0.d. Historically, Alfresco would give no clues as to whether or not they considered that a stable or final release. Subsequently, people would just grab the latest release and install it, which led to all sorts of problems. (See “Alfresco Community Edition needs sensible version labels“).
Now, thankfully, Community Edition releases are either Early Access (EA) releases or Generally Available (GA) releases. The EA releases are essentially snapshot releases that are stable enough for the community to try out and provide feedback on. The GA releases are stable builds. If you are running Community Edition in production, you should be running GA releases, not EA releases.
So the release we are talking about is “201602-GA” which means it was released in February of 2016 and it is GA. I don’t know what they are going to do if they have two GA releases in the same month, but I guess we’ll deal with that if it happens. Given that GA releases do undergo testing by Alfresco QA, which can take some time, two releases within the same month may be unlikely.
Alfresco is actually a collection of components. Community Edition 201602GA contains Alfresco Platform 5.1.e, Alfresco Share 5.1.e, Aikau 1.0.39.5, AOS 1.1, and Google Docs 3.0.3. Notice that Aikau, the client-side UI framework Share is built on, is included in that list as a separate component. The UI framework has been de-coupled from the rest of the platform–it now follows its own release cycle.
I consider this an awesome new “feature”, but let’s talk about real functionality actually in 5.1 Community Edition.
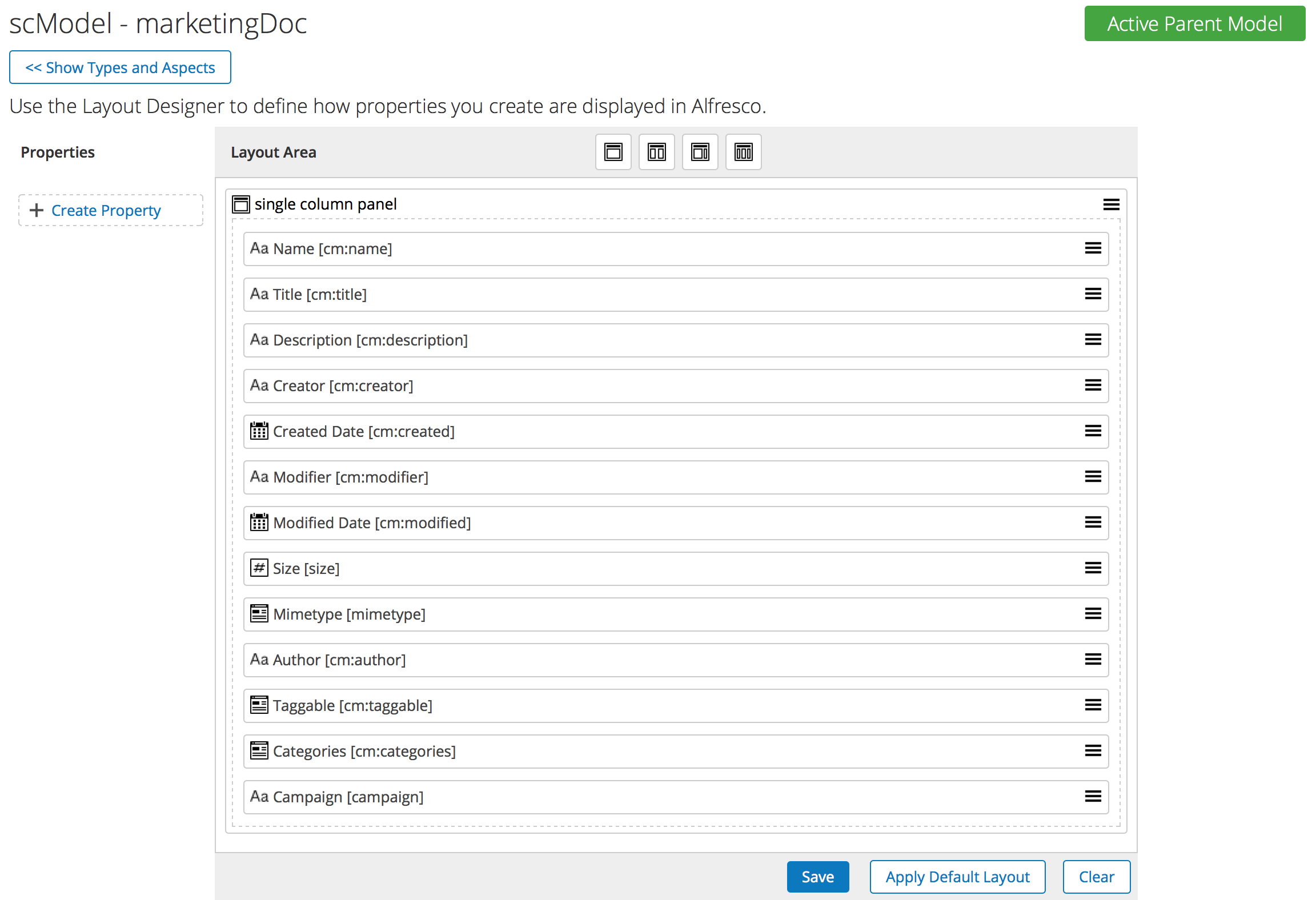
Content Modeling UI
If you’ve used other document management solutions and are new to Alfresco you may be surprised to realize that before this release, all content modeling had to be done by manually editing XML files. I know, I know, but the ability to define a content model in the Share UI is here now, so let’s be thankful.
Here’s how it works. If you are in the ALFRESCO_MODEL_ADMINISTRATORS group you’ll get access to a new admin panel called “Model Manager”. Creating custom types and aspects is a simple matter of point-and-click.
Beyond just defining the model, though, the UI also allows you to define the Share form configuration.
It’s pretty cool, although there are limitations:
Not everything supported by the underlying repository is supported by the content modeling UI. For example, I could not set mandatory aspects on a type and I could not define associations.
You can declare that properties must adhere to a constraint, but you can’t define the constraint once and reuse it across multiple properties.
I created the content model from my Custom Content Types tutorial but ran into a little problem. You can only inherit from types in an active model. I have an enterprise-wide type called “sc:doc” that my other types inherit from. The workaround is to create your enterprise-wide type first, then activate the model, then create your child types. Or you can put the enterprise-wide type in its own separate model.
I could not create items that inherited from sys:base or cmis:item (for content-less objects).
The advanced search form does not get configured to include custom types and aspects defined using the modeling UI.
The ability to define a content model without editing XML is a much-needed feature and I’m sure it will continue to evolve. It is extremely useful in its current form despite the limitations I’ve outlined above, which you can work around by using traditional techniques for defining the content model and Share form configuration.
Smart Folders
How many times have you wanted a folder to consist of query results rather than what’s physically in the file? The new Smart Folders feature gives you that capability. Unfortunately, it’s a little tedious to set up–it involves manually editing a JSON file to define your virtual folder structure. But, once you do that, it opens up a lot of possibilities.
If you aren’t sure why you’d want to define a folder as the results of a query, think about how you like to organize your files versus how other teams or departments like to organize theirs. Often, folder structures are optimized based on the work being performed. When different people with different roles work on the same content, it can become hard to create a folder structure that meets the needs of all constituents. Smart Folders allow you to set up alternative folder structures based on arbitrary criteria.
Imagine a college that facilitates internship assignments on behalf of their students. The best way to organize internship applications submitted by students depends on the person’s role. A student wants to see their own application. A counselor might want to see all of the applications for the students assigned to them. An employer wants to see the applications submitted to their company. And the internships coordinator wants to see applications by status. Prior to Smart Folders there’s not a great way to make all of these constituents happy.
In addition to creating search-defined folder structures, Smart Folders provides the ability to assign document types, aspects, and metadata values to documents automatically as they are added to the repository. For example, if you are a paralegal adding deposition transcripts to a case you no longer have to assign the cause number, client’s last name, and the fact that it’s a deposition. That gets assigned automatically based on where you uploaded the document.
To get a better feel for this, check out the Smart Folders documentation and tutorial. Alfresco has done a great job with it.
One last thing on Smart Folders–you may be wondering if a Smart Folder is accessible via CMIS. The answer is yes. Smart Folders are “normal” folder objects with an extra aspect applied (“smf:smart”). This has the potential to simplify CMIS code. Instead of putting the query in the code, you can define it in the folder template and in CMIS, just get the folder’s children which will be the query results.
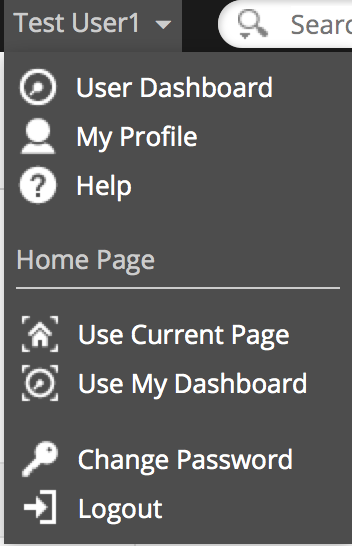
Default landing page
This is another frequently-requested feature: The ability for a user to define which page should be displayed upon logging in to Alfresco Share. Now it’s easy. Just navigate to the page you want to use as the default, click your user name, then click “Use Current Page” to set.
The next time you log in you’ll go to that page.
Become Owner UI action
Sometimes you have cases where you’d like to take over ownership of a document. One example is someone who has collaborator access. Collaborators can edit and delete documents they create because creators are owners. But maybe at some point you’d like them to be able to comment on documents in a folder but you don’t want them to edit documents even if they are the ones who uploaded them. One way to fix that is to have another user, such as a Coordinator, take over ownership of the document. This has always been possible, but before 5.1 you had to write your own script or UI action to make it happen. Now the UI action is available out-of-the-box.
AOS (Alfresco Office Services)
Alfresco Office Services is the new name for the re-implementation of the Microsoft SharePoint Protocol, which allows Microsoft Office products to enjoy native integration with the repository. If you have to use Microsoft’s office products at least you’ll be able to edit and save them directly to Alfresco.
While this is essentially the same functionality as the old SharePoint Protocol support, it does represent a significant change in Alfresco’s open source stance. Until now, all Alfresco Community Edition code has been 100% open source. Alfresco has chosen to include AOS with Community Edition, which is great, but it is distributed under a proprietary license. If that is a problem for you, the module is optional. You can still use the old open source implementation of the SharePoint Protocol, but it won’t be developed further by Alfresco. It sounds like they’ll spin it off as a separate open source project in case anyone is interested in maintaining it going forward.
jBPM has been jettisoned
Alfresco’s original embedded workflow engine was JBoss jBPM. Then, Activiti came along, and you could use either one. Eventually jBPM was marked as deprecated. With 5.1, jBPM has finally been removed from the release. Honestly, this should not be a surprise at all–you’ve had plenty of time to get your custom workflows moved over to Activiti.
SDK release lagged
I’m excited about the new release naming nomenclature and the new features. But one thing that is a little annoying is that the SDK that works with 5.1 lagged behind the release of the platform. So if you’ve got customizations that leverage the Alfresco Maven SDK, you couldn’t easily port those over in time for the release–you had to wait for the SDK. I haven’t heard whether or not this was a one-time occurrence or if this will always be the case.
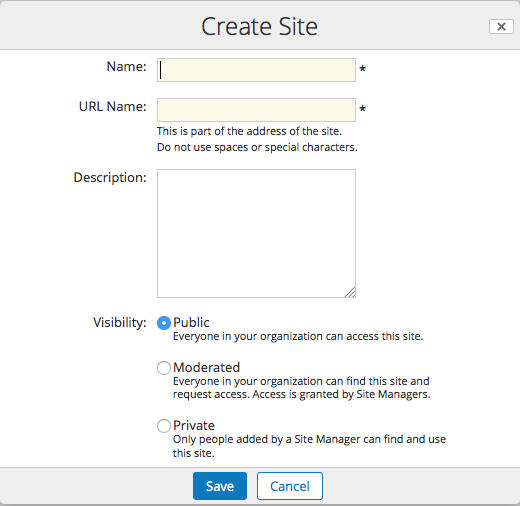
Share Site type is gone
I’m not sure why it was removed or if it is coming back, but the “site type” dropdown has been removed from the “Create Site” dialog. Maybe Alfresco thought this feature wasn’t used much. If you’re using my Share Site Space Templates add-on, this will affect you because you won’t be able to specify a custom site preset that maps to your Share Site folder template. I haven’t looked at the source yet–it might not be a big deal to re-enable this.
UPDATE: The Share Site type dropdown is not gone. It shows up when there is more than one type of site defined. This is a nice new feature in 5.1 because previously the dropdown would show up even if there was only a single choice.
That’s what’s new with Alfresco 5.1 Community Edition. Download it and try it out for yourself. If I’ve missed anything be sure to let me know in the comments.
And if you’d like to see any of these features live, check out my screencast:
(If the video doesn’t show up for you, here is the link).
Earlier this month, Google announced that it is getting out of the search appliance business. According to this article by Fortune, Google told its partners they could renew existing Google Search Appliance (GSA) customers through 2017 but no new hardware would be sold.
I have multiple clients running GSA for Enterprise Search and their experiences have been mixed. Clearly, the plug-and-play nature of a turnkey appliance was attractive. But, of course, the other side of that coin is the potential set of limitations that an appliance places on you, whether that’s in terms of cost/license, capacity, or features.
GSA customers have time to figure out their migration path. Google says they are working on a cloud-based alternative. But maybe it’s time to take a step back and consider your options.
Something big has happened since the last time you looked at Enterprise Search: It’s called Elasticsearch. The commercially-supported open source software builds on the rock solid foundation of the well-known Apache Lucene by baking in clustering and a comprehensive API out-of-the-box.
Adoption has been swift. At last year’s Elasticon conference, the company reported 20 million downloads. At this year’s conference the company announced they had hit 50 million downloads across all of their products.
Deployment options
If you want to self-support, you can set up a cluster on-prem and scale it as big as you need it for the cost of your time and some hardware. If you need commercial support you can get it from Elastic.
If a cloud-based solution is attractive to you there are several options:
Elastic has its own cloud offering called Elastic Cloud (formerly called “Found”).
Amazon offers its own hosted Elasticsearch offering called Amazon ES.
And you can always just grab some virtual machines on your cloud provider of choice and install and run your own cluster.
The Elastic Stack provides the core search platform and a host of other tools, but it does not provide a web crawler. You’ll probably want to use Scrapy, StormCrawler, or Nutch for this, all of which are freely available as open source software.
Beyond crawlers there are a ton of different ways to get content indexed into Elasticsearch. Beats and Logstash are two Elastic products that can be used to pump data into the cluster. If you have to write your own integration, the API is fairly straightforward and is available for a number of languages as well as anything that can speak REST.
You’ll be shocked at how quickly you can stand up an Elasticsearch cluster. Where you’ll likely spend more time is on production-izing your setup and tuning for relevancy (take a look at the Relevant Search book from Manning).
Your GSA was only ever going to be good at one thing–providing keyword search for your internal documents. Elastic gives you that and so much more. You might start out using it to replace your GSA-based Enterprise Search but you’ll soon figure out that it can be used for all kinds of interesting things.
A common request is to integrate the Alfresco Share calendar with an external calendaring system such as Outlook, Google Calendar, or Zimbra. Without an integration, people end up doing double-entry. You’ve already got a calendar that works pretty well. Why make people re-enter events in Alfresco Share?
Most people use Alfresco Share for team collaboration. The calendar doesn’t need to show everything on everyone’s calendar–that job is better left to the existing calendar server. What makes more sense is to show a few team-related events or milestones on the team’s Alfresco Share site calendar or maybe in a dashlet on the site’s dashboard.
When thinking about the problem, I realized that the calendar in Share is just another interested party in an event. Just as some calendaring systems allow you to “invite” a conference room to a meeting which effectively reserves that room for the meeting, you ought to be able to “invite” a Share site and have the Share site add that event to its calendar and update it when the event changes.
Treating the Share site as just another invitee is a non-invasive way to integrate with the calendaring system and it has the added benefit that only events in which the Share site was specifically invited will show up on the Share site calendar.
As luck would have it, the pieces to make this work already exist and they don’t require any changes to the source calendaring system. Check it out:
When you invite someone to a calendar event the calendaring system sends an iCalendar (.ICS) file as an email attachment to the invitee. The invitee’s email or calendaring client recognizes that attachment and updates the calendar accordingly.
There’s a Java library called iCal4j that knows how to parse iCalendar files. Yea for standards!
Alfresco supports receiving inbound email and you can easily bind custom logic to the creation of nodes. Alfresco creates one document for the email body and one for the ICS file attachment.
Events that show up on the Alfresco Share calendar are just content-less objects–they are instances of ia:calendarEvent.
Put those pieces together and a simple one-way calendar integration is born. The integration watches for incoming email with ICS attachments, parses the attachment, then creates, updates, or deletes the corresponding Alfresco Share site calendar object.
With this in place, all you have to do to add an event to the Alfresco Share site calendar is invite the Share site to the event from your favorite calendaring system.
But what’s the invitee name of a Share site? Great question! In Alfresco, there’s an aspect called email alias. You can add it to any folder and give it an arbitrary value. Then, when sending email to Alfresco you can specify the alias.
My integration includes code that makes sure all Share sites have a folder that can be used to store inbound email and it gives that folder an alias equal to the Share site’s short name (which is used as part of the Share URL). So if your Share site is called “test-site-1” and you normally send email to Alfresco via alfresco.someco.com, your Share site’s email address becomes test-site-1@alfresco.someco.com.
What about updates? Calendar systems have a universal identifier for every event. When calendar entries are updated or deleted, the calendaring system sends an iCalendar file just as it does for new events. Included in that file is the event’s unique ID and a flag that indicates whether the event is being created or deleted. When the integration creates the event in the Alfresco Share calendar, it stores the unique ID in the Alfresco object’s metadata which it can use later to match up subsequent update and delete requests.
How about a demo?
This video shows the integration in action. Be sure to make it full screen and select “HD”.
(If you can’t see the video, watch it on YouTube here).
What’s left to do?
This is a simple, one-way integration. It does not tell the corporate calendaring system which sites are available and it does not do a free-busy lookup. It also does not acknowledge the invitation back to the source calendaring system. I don’t consider these to be critical gaps but those features might make the integration tighter.
As a side-note, the automatic creation of an email alias for a Share site and a corresponding folder to hold inbound email (which users could then configure rules for) might be useful as a separate add-on even if you don’t need calendar integration. If you agree, let me know. Maybe the integration ought to be split into two separate AMPs.
Pull requests welcome
As usual, I welcome your participation on this project. If you find problems, fix problems, or want to make improvements, use the github project to create issues and pull requests.
Elasticon 2016 is just around the corner. The annual conference covering all things Elastic is happening February 17 – 19 in San Francisco.
Last year, the buzz was all about Elasticsearch 2.0. Attendees learned a lot about what to expect with that release. But my favorites were the sessions that covered real world implementations. Some of these included:
How the U.S. Geological Survey uses Elasticsearch to be notified of earthquakes as they happen by monitoring and analyzing social media.
Verizon’s best practices around scalability–they have 128 nodes indexing 10 billion documents per day.
Goldman Sachs was another big one–at that time they were running 700 nodes.
Interesting case studies from Wikimedia, Quizlet, Zen Desk.
Focus on analysis challenges from the team that runs Elasticsearch to provide web search for 1500 dot gov web sites such as the NIH and the U.S. Army.
Beyond informative sessions, you can learn a lot in the hallway track. At last year’s conference there were 1300 attendees from 32 different countries. I met people from both ends of the business spectrum doing all sorts of different things with Elasticsearch and the rest of the ELK stack.
This year’s agenda looks pretty interesting. I’m looking forward to the roadmap sessions, of course, but it’s the sessions from folks like Thomson Reuters, Yammer, HotelTonight, Eventbrite, Etsy, The New York Times, and Adobe that will probably give me the most bang for my buck. It only takes a few key insights here and there to pay for the entire trip.
Amazingly, this year’s conference has not sold out yet. Grab a spot and join us. Today is the last day for the discounted rate.
Registration for BeeCon 2016 is now open. What the heck is BeeCon? BeeCon is the first-ever, independently-organized conference focused entirely on Alfresco. The BeeCon web site says it best:
Alfresco professionals and enthusiasts come to BeeCon to sharpen their technical skills and collaborate with other experts…Whether you are a developer, information professional, student, or Alfresco employee, BeeCon is the place to dive deep into Alfresco and develop the relationships which you will need to be successful in the coming year.
The conference is organized by the Order of the Bee, an independent community focused on Alfresco.
Who Will Attend?
BeeCon is an event organized by and targeted towards the Alfresco community. It is built around the idea that what makes our community great is its open, collaborative spirit. And that, from time-to-time, it is important to meet face-to-face to learn from each other, hash out ideas, strengthen personal relationships, and just have fun.
If Alfresco is just a piece of software to you, then this is a conference with a lot of technical how-to’s that will help you get your project done, and you should come for that reason. When you arrive, though, you’re going to find out that a lot of people have crossed oceans and continents to be in Brussels because not only is the software important, but because, as a community, we have a lot of work to do. And the people who care about the Alfresco community are using this event to get organized and to map the way forward.
If you love sales pitches and marketing fluff you should sit this one out. But if you…
want to learn more about the technical details from experts;
are already running Alfresco in your organization, whether that’s Enterprise or Community Edition; or
want to help shape the future of the community and the platform
…then you need to attend BeeCon 2016.
More than a Meetup
This is more than a meetup. It’s a real two-day conference with keynotes, tracks, and a hack-a-thon. The goal is to make it similar to past events like DevCon with really great content and outstanding people, but without the big budget (or price tag).
You can register now for about 60 Euros. If you wait the price goes up to about 90 Euros.
Support from Alfresco and Other Sponsors
The BeeCon team has focused on keeping things practical and inexpensive. But events like this simply cannot succeed without help from sponsors. This year, CIRB-CIBG is providing the venue, A/V equipment, and WiFi, which is amazing because those three items are the biggest in terms of cost for any event. What’s even more amazing is that we enjoy additional support from a number of sponsors including Alfresco, Contezza, ITD Systems, keensoft, VDEL, and Xenit. You should thank these folks when you see them.
Stay Tuned for the Detailed Agenda
The program team received a number of speaking submissions from Alfresco engineers and community members from all over the world. They are busy reviewing those and will get the conference web site updated as things solidify. The team is picky–they want sessions to be high quality and packed with information you can use on your Alfresco projects right away. I’m looking forward to seeing the finished agenda, but I’m not going to wait to register.
Space is Limited, Do Not Wait to Register!
While you’re thinking about it, complete your registration. It’s only 60 Euros. I’ll bet you can slip that into an expense report without much fuss. And when you bring the things you learn back to the office, you’ll win respect and adoration from your boss and coworkers. Not bad for 60 Euros.
When making your travel plans for Brussels, remember that we’ll be getting together Wednesday night, April 27, for a welcome reception. The conference runs two days, April 28-29. Then, whomever is interested can come with us to the medieval city of Bruges on Saturday, April 30, for a day of sightseeing. I’ve been to Bruges–it’s gorgeous. You won’t want to miss it. Plus, it will be nice to hang out with your favorite community members, Belgian-style.
I look forward to seeing you in Brussels in April!
One of my clients came to me with a problem: Despite being a much-admired Fortune 500 company that leads its competitors in the travel industry in customer satisfaction and profitability, their web site, through which the vast majority of their revenues flow, was still mostly static. That by itself is not a huge problem, but they felt like they weren’t able to target content based on their customers’ needs and interests as well as they could with a more dynamic content engine.
It just so happened they were about to re-implement their site from mostly server-side to mostly client-side which is a huge undertaking. They figured that would be a pretty good time to add a dynamic content service to the mix, so they called me.
From Static to Dynamic
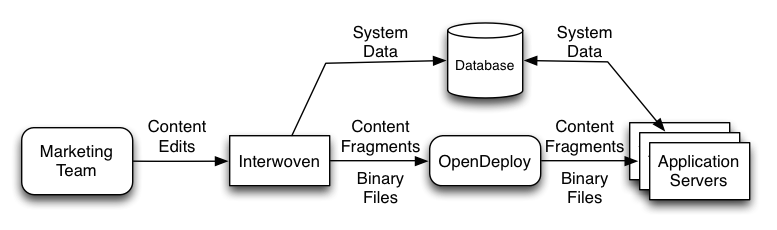
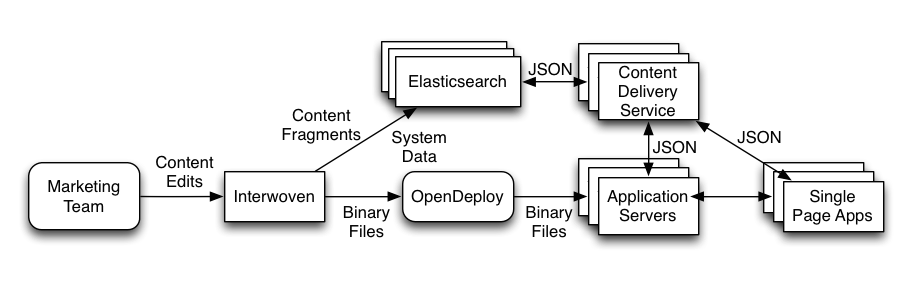
The diagram below depicts the high-level setup before the introduction of the content service.
This is pretty standard for sites like this. The Marketing Team edits content in a Content Management System (CMS), which in this case is Interwoven. Through various processes, binary files (mostly images), system data (things like lists of destinations and hotels), and content fragments are published out of Interwoven to destinations accessible by the e-commerce application.
A content fragment is literally a piece of content. It might be a promotion of some sort. Or it could be some text that gets used as part of a banner. The challenge using this setup is that content fragments are static files that live on the file system. If you want to show a different fragment based on something you know about the user you have to generate every permutation you might want ahead-of-time, publish them all, then use logic in the application to decide which one to use.
One obvious way to address this is to publish content fragments in a relational database and then code the front-end app to query for the right content. That wasn’t appropriate here for a few reasons:
The front-end is being migrated to a collection of Single Page Applications (SPA’s) written in JavaScript. It’s easier for those pages to call a RESTful API to get JSON back. Yes, you could still do that with a relational database and a service tier, but the client was looking for something a little more JSON-native.
The structure of the content changes over time. We wanted to be able to accept any kind of content fragment the Marketing Team or SPA developers could think of and not have to worry about migrating database schemas.
The anticipated style of queries needed to find appropriate content fragments was more like what you’d expect from a search engine and less like what you might put in a SQL query–we needed to be able to say, “Here is some context, now return the most appropriate set of content fragments for the situation,” and be able to use relevancy scoring to help determine what comes back.
So relational databases were ruled out in favor of document-oriented NoSQL repositories. Ultimately, Elasticsearch was selected because of its ease of clustering, high performance, unified REST API, availability of commercial support, and add-ons such as Shield, Marvel, and Watcher that make it easier to integrate with the rest of the enterprise.
Introduction of a Content Delivery Service
The first thing we did was stand up an Elasticsearch cluster, load some test data, and beat the heck out of it (see “Using JMeter to Test Elasticsearch“). Once we were satisfied it would be able to handle more than the expected load we moved on to the service.
The Content Delivery Service sits between Elasticsearch and the front-end applications. Its purpose is to abstract away Elasticsearch specifics and to protect the cluster by providing a simple, read-only REST API. It also enforces some light business logic such as making sure that only content that is currently effective according to its publication and expiration date is returned.
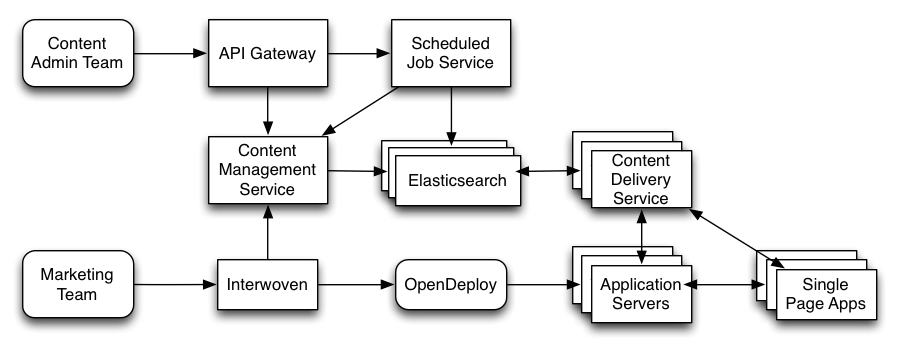
The diagram below shows the content infrastructure augmented with Elasticsearch and the content delivery service.
As seen in the diagram, Interwoven is still the source of record and the primary way Marketing manages their content. But now, content fragments and system data are published to Elasticsearch. The front-end Single Page Apps ask the Content Delivery Service for content based on some set of context. The content is returned as a collection of JSON objects. The SPAs then take those objects and format them as needed.
Content Objects are Pure Content
A key concept worth emphasizing is that a content object is pure content. It contains no markup. It might have some properties that describe how it is expected to be used, but it is completely lacking in implementation. This has several benefits:
Content objects returned by the Content Delivery Service can be used across any and all channels (such as mobile) rather than being specific to a single channel (such as web).
Within a given channel the same object can have many different presentations.
Responsibilities are cleanly separated: The content service provides content. The front-end applications style and present the content for consumption.
This was a bit of a departure from how things used to be done. In the bad old days presentation was always getting mixed up with content which severely limits reuse.
Micro-services Provide Administrative Features
I mentioned earlier that the Content Delivery Service is read-only. And in my previous diagram I showed Interwoven talking directly to the Elasticsearch cluster. In reality, we don’t let anyone talk directly to the Elasticsearch cluster. Instead, all writes have to go through the Content Management Service. This ensures that we know exactly what is going into the cluster and who is putting it there.
The other role the Content Management Service plays is JSON validation. When new types of content objects are developed we use JSON Schema to codify the structure. When a person or system posts a content object to the Content Management Service, the service validates the object against its JSON Schema before storing it in Elasticsearch.
In addition to the Content Management Service we also implemented a Scheduled Job Service. As the name suggests, it is used to perform administrative tasks on a schedule. For instance, maybe content needs to be reindexed from one cluster to another in a lower environment. Or maybe content needs to be fetched from a third-party and written to the cluster. The Job Service is able to talk to either the Content Management Service or Elasticsearch directly, depending on the task it needs to execute.
All of the administrative services are independently deployed web applications that sit behind an API Gateway. The Gateway leverages the Netflix Zuul Proxy. It is responsible for authenticating against LDAP and creating a shared session in redis. It gives the content admin team a single URL to hit and isolates authentication logic in a single place.
The diagram below shows the fully-realized picture.
A few key components aren’t on the diagram. We use Shield to protect the Elasticsearch cluster. Shield also makes it easy to configure SSL for node-to-node communication and provides out-of-the-box LDAP integration. With Shield we can map LDAP groups to roles and then grant roles various privileges on our Elasticsearch cluster and its indices.
We use Watcher to monitor cluster health and job failures that may happen in the Scheduled Job Service. The client has their own enterprise alerting and monitoring solution, but Watcher gives the content management team a flexible, powerful tool for keeping track of things at a level that is probably more granular than what the enterprise ops team cares about.
Ready for the Future
With Elasticsearch and a few relatively small services on top of that, this travel giant now has what it needs to provide its customers with a more customized online experience. Content can be targeted to the users it is most appropriate for using any kind of context the Marketing team can come up with. As the front-end commerce app evolves, new types of content objects can be added easily and be served to the front-end with no schema or service changes required. And it’s all built on commercially-supported open source software.
I stumbled onto Elasticsearch’s search templates feature on my last project and it turned out to be really useful. I remember being surprised I hadn’t seen it mentioned anywhere. I’ve asked around at the last couple of meetups I’ve attended and it turns out many people don’t know about search templates, so I thought it might make a good post.
I’m going to give some context as to why this feature was useful, then I’ll show you how to use it. If you don’t want or need the context, feel free to skip to the next section.
Context: Real world use case for search templates
For this particular project we were using Elasticsearch as a content service. A set of front-end Single Page Applications (SPAs) query the content service. The content service returns content objects as JSON that match some criteria. Components in the SPAs format the objects as needed.
The content service is a Java-based API that sits between the SPAs and Elasticsearch. The API abstracts the Elasticsearch details and adds some business logic regarding which content to return beyond simply matching the parameters specified by the front-end.
A simple example of one type of business logic the API adds is publish date and expiration date handling. All of our JSON objects in Elasticsearch have a publish date and some have an expiration date. When the front-end asks the API for content, we only want to return content that is current–in other words the current date has to be greater than or equal to the publish date and less than the expiration date if an expiration date is set.
If you leave this up to the front-end, and if the API is open, then anyone can get any content object, regardless of effectivity, which, in our case, is a bad thing. Even if the API was locked down, there’s no reason to make each front-end application duplicate the date handling logic. So the API handles that and other business rules around fetching content and constructing a response.
The native Elasticsearch API is Java, so building and executing queries in Java is a very natural thing to do. However, as the service evolved, the part of our code responsible for constructing the query was at risk of becoming unwieldy. We also started to identify new types of queries the front-end needed to execute that didn’t fit cleanly into our existing query-building logic.
In addition to identifying new types of queries the API needed to support, we began to see that the front-end applications would need to be able to provide more than just a flat list of key-value pairs–at the very least they would need to ask for content with parameters that included arrays and dictionaries as well.
The service had reached a point where it needed flexibility in the number and type of queries it could run and the parameters it could accept, but we didn’t want to expose the full power (and complexity) of the Elasticsearch Query DSL. Search templates to the rescue.
What is an Elasticsearch Search Template?
(This section contains embedded gists. If you can’t see them you may need to enable JavaScript. If all else fails, the gists live here.)
An Elasticsearch search template is kind of like a stored procedure in a relational database. Really, it’s just a normal query with replacement variables, aka template parameters. The templates are expressed using Mustache.
Here’s a simple example:
That example specified the template and the parameters in the same request. Obviously, if you’re going to do that you might as well not use a template.
What you’d rather do is put the template somewhere and then invoke it. You have two options. You can index the template or you can put the template on the file system.
Here’s how you index a template:
And then you can call it, like this:
If you’d rather put the template on the file system, it goes in $ES_HOME/config/scripts and is named template-id.mustache. Once you’ve deployed the template to every node in your cluster, you can call it, like this:
You don’t have to restart the node when you update a search template. Elasticsearch picks up the changes automatically. If you watch the log when you update a search template you should see something like:
Suppose we want to return all tweets unless a “since” parameter is provided. If since is specified, the query should do a date range against the timestamp property using the value provided. Mustache has some support for conditionals. Here’s how it looks in a search template:
This template will conditionally add the date range check only if the “since” parameter is provided.
Note: Be careful of spacing here. I like to put a space between my curly braces and the parameter. But if you do that in the conditional, mustache won’t recognize it.
To get the tweets for the last 30 days, you’d call the search template like this:
And to get all of the tweets you’d just omit the since parameter.
As your templates get more complex you might take a look at this tool. It allows you to quickly see how your templated queries will render given a set of parameters.
Using negation to implement if-then-else logic
Suppose that instead of returning all tweets we want to return just the last day of tweets unless the since parameter is specified. You’d like to use an if-then-else in the Mustache template. Else isn’t specifically supported by Mustache, but we can use negation to achieve the same thing.
This template keeps the clause that does the date check if since is specified, but now adds a default date check if it is not:
If the date is specified in the since parameter, it works as it did before. If not, only the last day of tweets will be returned.
Working with Arrays
Something that is kind of annoying is how to handle arrays. You can iterate over an array with Mustache fairly easily. But Mustache doesn’t have a mechanism for checking a position in an array such as “isLast” or “hasNext”, so if you need to do something like that, you’ll end up making your own construct.
For example, suppose we want to be able to pass in a list of user names to the search template to restrict the list of tweets to those specific users. The easy way to handle that in our query is to use a terms filter, like this:
But that doesn’t let me show how to work with arrays so I’m going to contrive the example to say that if a user list is provided, we need to add an “or” clause to the query with one term filter per user name.
To do that, we’ll require the list of users to be provided as a search template like this:
The template can check for the “userList” parameter to know whether or not to build the “or” clause. Then it can iterate over the “users” array, plucking out the name.
As the template iterates over the array, it needs to know whether or not it is on the last user. Otherwise it has no way of knowing whether or not to add the comma separating the term filters. Mustache can’t help us so the search parameter will include “isLast” set to true for the last user in the list.
Here’s a template that can handle the array of user names:
The result of calling the template above with the example user list is a query that looks like this:
With those simple constructs you ought to be able to create some very elaborate search templates.
Invoking search templates from the Java API
Back in the service layer, it is easy to invoke a search template with the Java API. Here’s how that looks:
In the real API, those params are getting POSTed to the endpoint.
Query changes without a code deployment
With search templates, we can add new queries and modify existing queries by creating and modifying search templates. This means for many adjustments, we don’t have to build and deploy the custom content service API code. And troubleshooting is easier too because we can invoke the same search template the service is using directly and not worry about whether or not the Java API is building the query we expect.
So the next time you find yourself writing code to construct an Elasticsearch query, ask yourself if it would make more sense to externalize it as a search template.

 Well, Justin, high school graduation is behind you, you’ve landed in San Jose, and tomorrow morning you’ll wake up in Mountain View to start your internship at Mozilla, your first real world, paying job that’s aligned with your career goals.
Well, Justin, high school graduation is behind you, you’ve landed in San Jose, and tomorrow morning you’ll wake up in Mountain View to start your internship at Mozilla, your first real world, paying job that’s aligned with your career goals.